使用pandas进行数据处理
最近开始学习pandas用来作为数据分析的入门,这里将最近的学习所得记录在这里,以作小结。
pandas简介
pandas是一个开源的数据结构化和分析工具。它的出现是为了解决Python语言在数据分析和建模方面的缺失,让工程师可以在数据采集和分析方面采用同样的语言,而不需要切换到专门的分析语言如R。
pandas依赖于numpy,提供了一个非常有效的数据结构DataFrame,可以把DataFrame想象成Excel的工作表,它可以提供非常有效的组织和索引功能。
另外,pandas提供了API用于读写多种类型数据,包括:
- CSV
- Excel
- SQL database
- HDF5
- JSON
- 剪贴板
- …
而借助于Jupyter notebook,pandas可以方便地进行数据的分析和可视化,如我学习用的notebook。
iPython简介
ipython最初是作为一个增强型的交互式python shell创建起来的,现在它已经成为python数据分析和可视化的一个不可或缺的工具。在日常的Python开发中,它的使用频率已经远超过IDE,对于笔者来说,ipython+vim作为Python开发环境非常高校。
安装
ipython的安装非常简单,通过pip就可以了。 通常,我们在安装完ipython后,还会安装jupyter,因为我们需要用到notebook和qtconsole之类的功能。这个中间有些模块需要另外安装,根据错误提示来就可以了。
- 安装ipython:
pip install ipython - 安装jupyter:
pip install jupyter
笔者的工作电脑是Macbook,在Linux上也适用,但如果你用的是Windows,通常你还需要安装一下pyreadline,通过pip install pyreadline就可以安装了。
使用
在一个Terminal工具(如iTerm2)里执行ipython就可以进入ipython。
执行jupyter qtconsole或jupyter notebook就可以打开qtconsole和web notebook了。比较推荐notebook的模式,因为在notebook中可以混合markdown、代码、执行结果和生成的图表,本身就是一份活的文档了。
ipython相比默认的python shell有很多优点,至少包括:
- 自动补全,输入几个字符按Tab
- 文档查看,在模块或变量名前加?执行,如
?os - 执行系统命令,在命令钱加!,如
!ls - 执行文件,如
%run test.py - 内嵌显示图表(需qtconsole或notebook)
jupyter notebook作为交互式的web notebook,可以极大地提高效率,因为:
- 将代码和执行结果融合到一起
- 将生成的图表嵌入到notebook中
- 可以添加markdown用于说明和文档
- web形式便于分享
ipython有内置的性能分析方法,可以方便地分析函数的性能,包括:
- %time ==> 获得程序运行的时间
- %timeit ==> 持续运行100万次,分析函数所用时间
- %prun ==> 以cProfile的方式运行函数进行性能分析
pandas入门
在利用Python进行数据分析这本书的引言部分有三个例子,我在pandas 0.17.1版本上把他们都实现了一下。 通过这三个例子,我们可以一窥pandas数据分析的门径。
例子-1:分析网页请求数据
在http://1usagov.measuredvoice.com/2013/上可以下载到网页请求数据,我们选取其中一天的数据文件usagov_bitly_data2013-05-17-1368832207来进行分析。
这个文件的每一行都是一个json字符串,因此我们可以很方便地把它按行转换成一个list。
import json
# 数据来源: http://1usagov.measuredvoice.com/2013/
with open('usagov_bitly_data2013-05-17-1368832207') as fp:
records = map(json.loads, fp)
我们会将上面得到的records转换成pandas的DataFrame对象,以进行后续的处理。这里我们希望通过简单的方法可以过滤出我们需要的数据。
from pandas import DataFrame
data = DataFrame(records) # 以frame形式使用数据
data[(data['tz'] == '') & (data['al'] == 'en')] # filter data
# 也可以使用
data[(data.tz == '') & (data.al == 'en')]
上面的代码将时区(tz)为空,并且语言(al)为en的数据过滤出来。
很多时候我们的数据集中的某些数据会存在一些字段的缺失或异常,pandas可以很方便地进行这方面的清洗和处理工作。
clean_tz = data['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
fillna方法将所有没有tz字段的数据的该字段值设置为Missing,而第二行代码则将所有tz为空的数据改为Unknown。
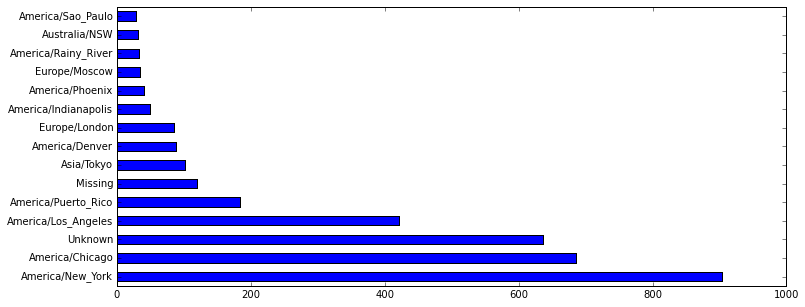
上面的clean_tz记录了所有这些数据的时区信息,我们希望知道每一个时区的访问次数并排序,这个时候我们可以采用value_counts方法。
%matplotlib inline
clean_tz.value_counts()[:15].plot(kind='barh', figsize=(12, 5))
首先将matplotlib以inline方式显示,然后画图,这个图里面会显示最少访问的15个时区,如下图:
agents = Series([x.split(' ', 1)[0] for x in data.a.dropna()])
agents.value_counts(ascending=True)[-15:].plot(kind='barh', figsize=(12, 5), logx=True) # logx=True 使用对数坐标
这里使用dropna丢弃了所有无效的数据,并反序得到最活跃的15个Agent。由于这些数据差异较大,X轴采用对数坐标显示。
我们通过判断在data的a字段中是否包含Windows来判断这个请求是否来自Windows操作系统。
# 找出Windows和非Windows用户的比例
cframe = data[data.a.notnull()] # 过滤出字段a非空的数据
import numpy as np
# np.where的第一个参数是一个判断条件,如为True,则返回第二个参数“Windows”,否则返回第三个参数“Not Windows”
# 其效果类似:
# In [12]: np.where([True, False, True, True, True], 'a', 'b')
# Out[12]:
# array(['a', 'b', 'a', 'a', 'a'],
# dtype='|S1')
#
# 具体可以参照http://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.where.html
operating_systems = np.where(cframe['a'].str.contains('Windows'), 'Windows', 'Not Windows')
# 以时区和操作系统进行分组
by_tz_os = cframe.groupby(['tz', operating_systems])
# .size()方法会把操作系统统计出来,显示成:
# tz
# Not Windows 484
# Windows 152
# Africa/Cairo Windows 3
# Africa/Casablanca Windows 1
# Africa/Ceuta Not Windows 4
# Windows 2
# ...
#
# .unstack()会把堆叠在一起的Windows/Not Windows展开,成为:
# Not Windows Windows
# tz
# 484 152
# Africa/Cairo NaN 3
# Africa/Casablanca NaN 1
# Africa/Ceuta 4 2
# Africa/Gaborone NaN 1
# Africa/Johannesburg 2 NaN
# ...
#
# .fillna(0)则会把里面所有NaN的数据变成0
agg_counts = by_tz_os.size().unstack().fillna(0)
# 排序
# .sum(1)是以columns来累加,它会把Not Windows和Windows的数据加起来
# 如果sum的参数为0,则表示以index来累加
# .argsort()则会对值进行排序,返回一个numpy的ndarray indexer
indexer = agg_counts.sum(1).argsort()
indexer[:10] # 最前面10个数据
# .take(indexer)会以indexer来排序agg_counts,从而达到根据访问次数排序的目的
# 参照:http://docs.scipy.org/doc/numpy-1.10.0/reference/generated/numpy.take.html#numpy.take
count_subset = agg_counts.take(indexer)[-10:] # 最后10个数据
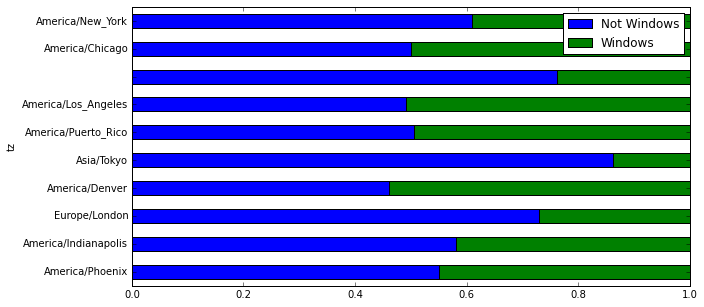
# 设置stacked为True以便将Windows和Not Windows堆叠在一起显示
count_subset.plot(kind='barh', stacked=True)
# 看比例而不看数据
# count_subset.sum(1)会将Windows和Not Windows的数据累加
# count_subset.div会将Windows和Not Windows的数据除以累加的数据得到比例
# 这里axis=0是必须的,默认是以columns来显示axis,这里设置为0,则会以index来显示。
# 见:http://pandas.pydata.org/pandas-docs/version/0.17.0/generated/pandas.DataFrame.div.html
count_subset.div(count_subset.sum(1), axis=0).plot(kind='barh', stacked=True, figsize=(10, 5))
最后生成的图如下:
例子-2:使用pandas来分析电影评分数据
在grouplens上有100万条电影评分数据,这是一个非常有用的数据集合,可以帮助我们发现许多有趣的信息。
里面还有三张表:
- users.dat
- ratings.dat
- movies.dat
分别是用户数据,评分数据和电影数据,是不是很像我们在关系型数据库里面的表设计?
这三张表的数据结构是一致的,都是按行文本形式,每行数据的各个字段以::分隔。读取这种类型的数据可以使用pandas的read_table方法。
类似关系型数据库的做法,我们需要把这三张表进行join,得到我们要的最终数据,相关的代码如下:
# 用户数据
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
users = pd.read_table('ml-1m/users.dat', sep='::', header=None, names=unames, engine='python')
# 评分数据
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('ml-1m/ratings.dat', sep='::', header=None, names=rnames, engine='python')
# 电影数据
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table('ml-1m/movies.dat', sep='::', header=None, names=mnames, engine='python')
# 合并为最终数据
mldata = pd.merge(pd.merge(ratings, users), movies)
我们希望对不同性别的观众在评价电影时的数据做一些分析,所以希望得到每部电影按性别划分的评分数据,这里我们需要引入pivot_table。
Pivot Table(数据透视表)是一种交互式的表,可以进行某些计算,如求和与计数等。 所进行的计算与数据跟数据透视表中的排列有关。 之所以称为数据透视表,是因为可以动态地改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。 每一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据。
我们希望对rating这个字段进行聚合,以title字段作为索引,并显示不同gender的信息,聚合的方式为平均数。见下面的代码:
mean_ratings = mldata.pivot_table('rating', index='title', columns=['gender'], aggfunc='mean')
如果评分记录过少,这些数据我们认为是特殊数据,需要在分析的时候过滤掉。要实现这一点,通过.size()函数就可以实现了。
# 得到按title为index的group,值为这个title出现的数量,也就是评分数量
ratings_by_title = mldata.groupby('title').size()
# 通过.index方法返回一个Indexer,这个index的过滤条件为值 >= 250
active_titles = ratings_by_title.index[ratings_by_title >= 250]
# 通过.ix方法得到active_titles里面包含的数据
mean_ratings = mean_ratings.ix[active_titles]
有了这个mean_ratings,我们就可以很容易地得到女性最喜欢的N部电影之类的数据了。如:
mean_ratings.sort_values(by='F', ascending=False)[:10] # 女性最喜欢的10部电影
mean_ratings['diff'] = mean_ratings['M'] - mean_ratings['F'] # 男性与女性的分歧
sort_by_diff = mean_ratings.dropna().sort_values.(by='diff', ascending=False)
sort_by_diff[:10] # 男性与女性分歧最大的10部电影(男性更喜欢)
mldata.groupby('title')['rating'].std().ix[active_titles].sort_values(ascending=False)[:10] # 不考虑性别因素分歧最大的10部电影
例子-3:使用pandas来分析新生儿姓名数据
在https://www.ssa.gov/oact/babynames/limits.html上有美国1880年到现在的出生婴儿姓名数据,每年一个csv格式的数据文件。
我们先把这些年的数据文件聚合成一个DataFrame,然后再用于分析。
from glob import glob
import re
year_ptn = re.compile(r'\d+')
pieces = []
for file_path in glob('names/*.txt'):
names_year = pd.read_csv(file_path, names=['name', 'sex', 'births'])
names_year['year'] = int(year_ptn.search(file_path).group())
pieces.append(names_year)
# 默认的index为行号,ignore_index=True 之后将不会返回原始行号,否则聚合后会有问题
names = pd.concat(pieces, ignore_index=True)
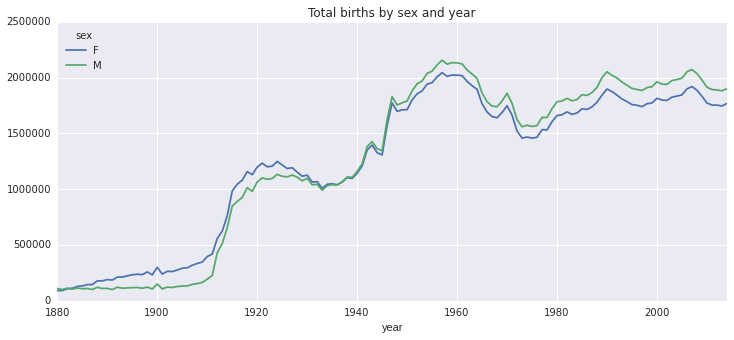
同样借助于pivot_table,我们基于births进行按年聚合,聚合的方式为sum。
total_births = names.pivot_table('births', index='year', columns=['sex'], aggfunc=sum)
total_births.plot(title='Total births by sex and year', figsize=(12, 5))
显示如下图:
要获得某个名字在历史上的出生数比较简单,通过一个基于births的pivot_table就可以获得了,如:
# 某个名字在历史上的出生人数
names[names.name == 'Mark'].pivot_table('births', index='year').plot()
但要获得这个名字如Mark在所有人中所占的比例,就需要先计算它的比例再绘图了。要达到这一点,我们需要借助一个apply函数。
# 指定名字的婴儿出生数占总出生数的比例
def add_prop(group):
births = group.births.astype(float)
group['prop'] = births/births.sum()
return group
# apply方法将每一个group进行add_prop运算,给这个group的数据加上prop属性
# 见:http://pandas.pydata.org/pandas-docs/version/0.17.0/generated/pandas.DataFrame.apply.html
names = names.groupby(['year', 'sex']).apply(add_prop)
# 有效性检查,所有名字的比例之和为1
np.allclose(names.groupby(['year', 'sex']).prop.sum(), 1)
通过add_prop函数,我们给每个数据加上了一个prop字段。然后用上面类似的手段就可以画图了。
all_births = names.pivot_table('births', index='year', columns='name', aggfunc=sum)
subset = all_births[['John', 'Harry', 'Mary', 'Marilyn']]
subset.plot(subplots=True, figsize=(12, 12), grid=False, title='Number of births per year')
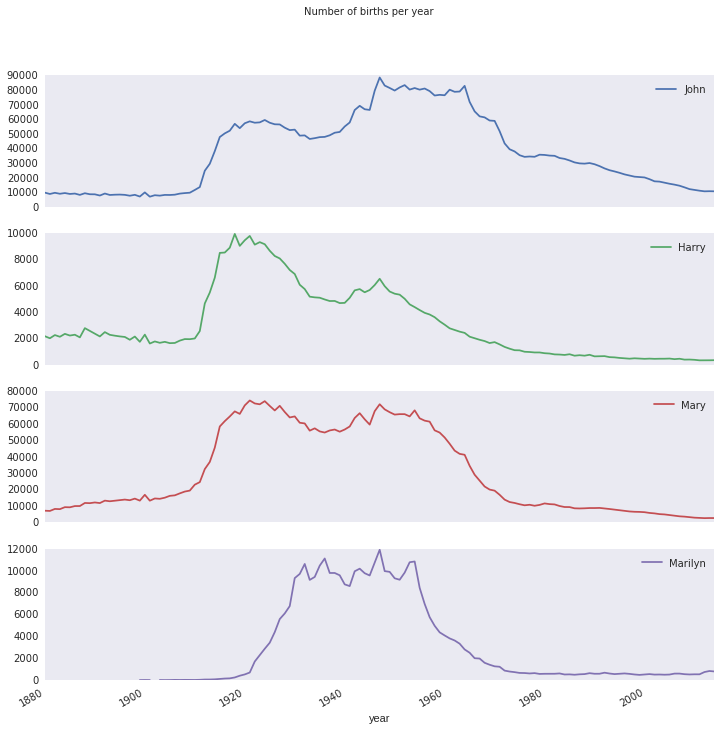
要想知道命名是否趋向多样化,首先需要知道top 1000的名字的新生儿有多少。
我们可以用两种方法来分析这个问题:
- top 1000的新生儿所占全部新生儿的比例
- 50%的新生儿所用到的名字数量
我们先得到top 1000的新生儿数据,同样采用apply函数。
# 取sex/year组合的前1000个名字
def get_top1000(group):
return group.sort_values(by='births', ascending=False)[:1000]
grouped = names.groupby(['year', 'sex'])
top1000 = grouped.apply(get_top1000)
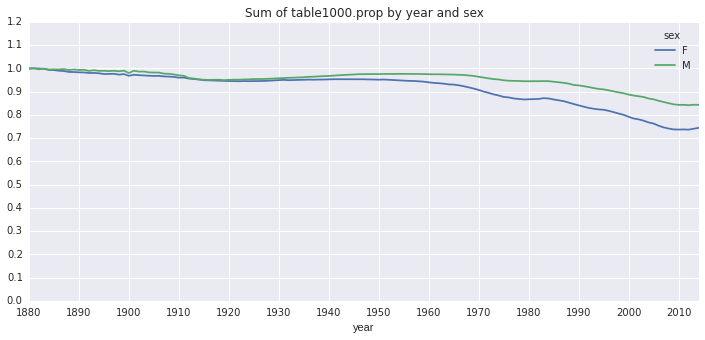
分析top 1000新生儿占全部新生儿的比例,这里区分了性别:
# top 1000姓名的新生儿占全部新生儿的比例
table = top1000.pivot_table('prop', index='year', columns='sex', aggfunc=sum)
table.plot(title='Sum of table1000.prop by year and sex',
yticks=np.linspace(0, 1.2, 13),
figsize=(12, 5),
xticks=range(1880, 2020, 10))
第二种方法,得到50%人数所需要的名字数。
关键是得到50%人数所需要的名字数,我们借助与searchsorted函数。searchsorted是一个来自numpy的函数,可以帮我们找到一个序列满足某个条件的插入位置,它的值加上1就是所需的名字数。
# 50%人数所需要的名字数
def get_quantile_count(group, q=0.5):
group = group.sort_values(by='prop', ascending=False)
return group.prop.cumsum().searchsorted(q) + 1
diversity = top1000.groupby(['year', 'sex']).apply(get_quantile_count)
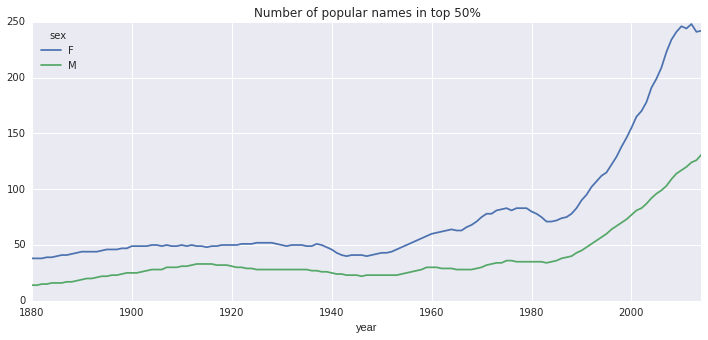
diversity = diversity.unstack('sex').astype(int)
diversity.plot(title='Number of popular names in top 50%', figsize=(12, 5))