Python设计模式 - MapReduce模式
MapReduce是一种从函数式编程语言借鉴过来的模式,在某些场景下,它可以极大地简化代码。先看一下什么是MapReduce:
MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
简单来说,MapReduce就是把待处理的问题分解为Map和Reduce两个部分。而待处理的数据作为一个序列,每一个序列里的数据通过Map的函数进行运算,再通过Reduce的函数进行聚合成最终的结果。
Map
一个典型的map用法是:
#mapper_data = map(func, data)
# 如:
str_lens = map(len, ['hello', 'world', 'to', 'you', 'and', 'me'])
# str_lens:
# [5, 5, 2, 3, 3, 2]
这个例子中,str_lens就是A‘,func就是函数len,['hello', 'world', 'to', 'you', 'and', 'me']就是A。见下图:
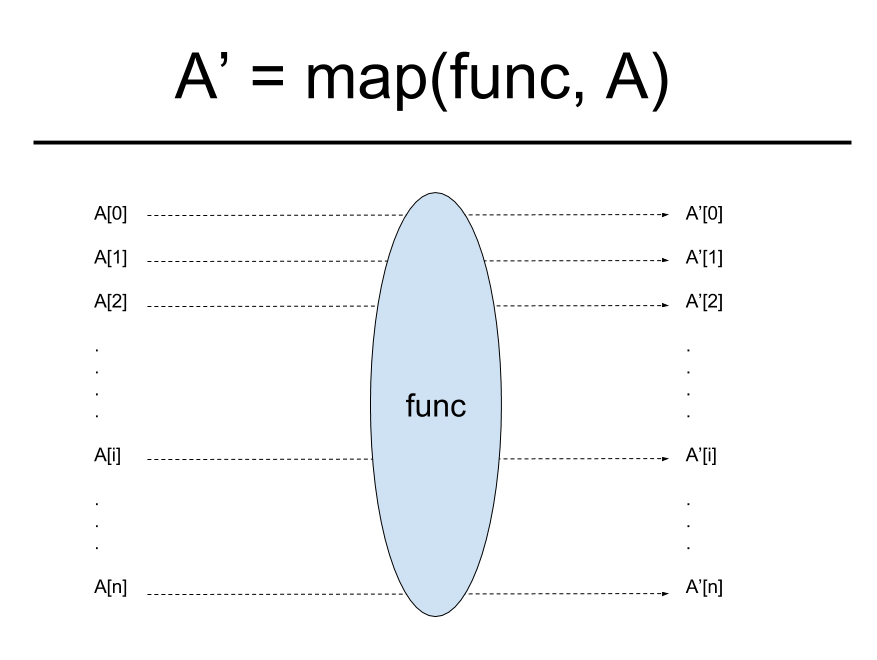
如果不用map,这个例子就得用列表推导或者for循环,从某种意义上说,列表推导也可以看作是一种map。
Reduce
reduce,顾名思义,是收敛和聚合的意思,最简单的用法如累加,把一个序列中的所有元素相加,见下面的代码:
reduce(lambda x,y: x+y, range(10))
# return: 45
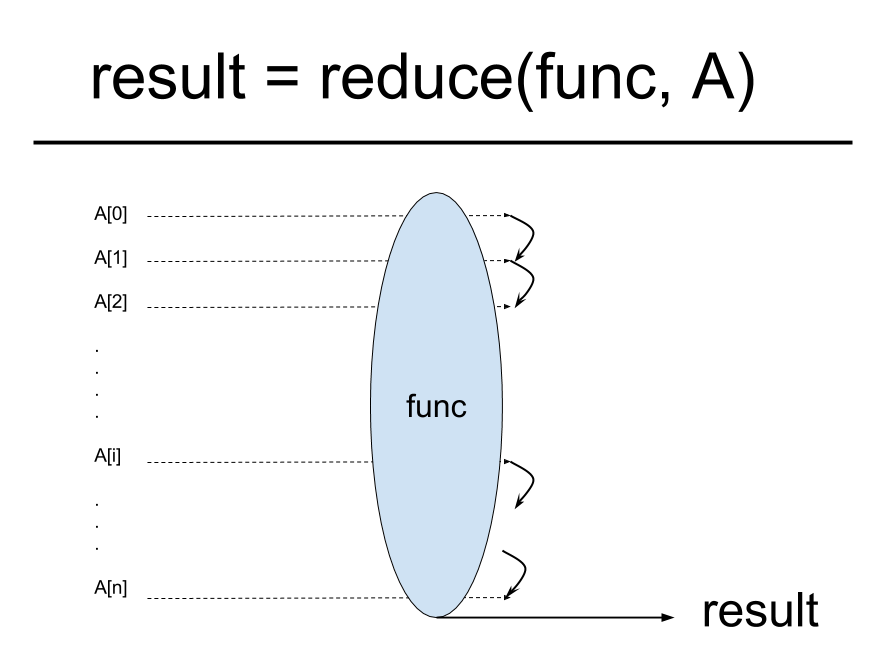
- A中的每一个元素,都会与上一次迭代的结果一起被func进行运算
- 每次运算的结果都会带到下一次迭代中,作为一个输入,和下一个元素一起计算
- 所有的元素运算结束,则得到最后的结果
一个真实的例子
# 实现一个to_int函数, 可以把一段字符串流转换成整数
# eg:
# to_int('\\xef') ==> 239
# to_int('\\xef\\x01') ==> 61185
# NOTE: builtin function ord can return the integer ordinal of a one-character string
这个函数通过mapreduce分解可以分为以下两个部分:
- 字符串流的每一个字符转换为整数
- 将这些整数以256进制运算,得到结果
最终的代码如下:
def to_int(hexstr):
return reduce(lambda x,y: x*256+y, map(ord, hexstr))
最后的代码只有一行,而且,即便这个hexstr是一个文件或者网络流也没有问题,这个代码可以正常工作。
需要注意,Python2.×版本中map函数的返回值是list,所以如果序列很大,请使用itertools.imap(见参考)。
并行的MapReduce
MapReduce模式是非常适合并行操作的,比如进程并行:
from multiprocessing import Pool
pool = Pool(8)
pool.map(ord, 'abcdefghijklmn')
# OUTPUT:
# [97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110]
或者线程并行:
from multiprocessing.dummy import Pool
pool = Pool(8)
pool.map(ord, 'abcdefghijklmn')
# OUTPUT:
# [97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110]