压力测试简介
压力测试的相关介绍,涵盖函数的benchmark、接口的压测、简单服务压测、分布式系统压测及压测工具的开发相关内容。
什么是压测
压测是一种通过人为的手段,以验证软硬件是否符合相关性能要求,找出软硬件容量上限等为目的的测试行为。
通常,进行压测主要来源于:
- 用户需求
- 资源规划
- 持续改进
举一个简单的例子,在移动运营商进行5G网络部署的时候,在一个5万人口的小区架设几个基站,它需要知道每个基站服务的范围,服务的用户数,上网带宽等等数据,没有这些数据,它就无法进行有效的基站规划,这时候就需要进行测试。
再比如,淘宝双十一,各项服务是否磨合就绪,流量上来之后能否有效限量,避免出现雪崩,诸如此类的问题都需要在之前通过压测来验证。
上面说的都是比较大型的系统,压测的场景也比较复杂,实际上,压测可以从很小的函数开始,而且大部分情况下,我们只需要关注函数和接口就够了。
压测从分析系统开始
首先需要明确系统的关键指标, 如:
- DNS服务每秒可以响应20W个查询请求
- 95%的查询请求响应时间在5ms以内
- 当请求量达到25W每秒时,其中的20W请求能正确处理,响应时间波动在5%以内
其次需要明确资源限制,如:
- 硬件:如网口速率,CPU核心数,内存大小,是否SSD,交换机速率等
- OS:如内核版本,是否支持zero copy,是否支持bbr等
- 应用软件:如asyncio,coroutine,GIL,是否采用DPDK等
接下来就需要定义压测的场景,如:
- A类内部DNS请求场景
- A类转发外部DNS请求场景
- AAAA类内部DNS请求场景
函数Benchmark
辛辛苦苦写了个xxtea的编解码函数,结果写完的时候发现github上已经有一个实现了,而且功能完全满足,这时候是不是很沮丧?别急,先喝杯茶,跑下benchmark,如果咱的实现性能更优,那就不用现成的,或者给人提个pull request。
像go这样的语言,内置了对benchmark的支持,实现起来很方便,只要写一个名字为Benchmark开头的单元测试就可以了,如:
BenchmarkEncrypt(b *testing.B) {
data := []byte("gvhaerutq vnp3h 7-q324bv571 5adhfadddf")
key := []byte("1231241adfsdfh3456sadfasdf")
for i := 0; i < b.N; i++ {
Encrypt(data, key)
}
}
这时候执行go test -benchmem -bench=. ./... -run=none就可以得到类似下面的结果:
➜ xxtea git:(master) go test -benchmem -bench=. ./... -run=none
goos: darwin
goarch: amd64
pkg: github.com/feiyuw/xxtea
BenchmarkEncrypt-8 3000000 531 ns/op 112 B/op 3 allocs/op
BenchmarkXXTeaGoEncrypt-8 2000000 650 ns/op 128 B/op 3 allocs/op
BenchmarkDecrypt-8 3000000 545 ns/op 112 B/op 3 allocs/op
BenchmarkXXTeaGoDecrypt-8 3000000 581 ns/op 128 B/op 3 allocs/op
PASS
ok github.com/feiyuw/xxtea 8.772s
上面的输出可以看到:
- 操作系统是MacOS,CPU是64为的Intel的(goos,goarch)
- 测试的包名为:github.com/feiyuw/xxtea
- 共测试了4个用例,其中类似
531 ns/op表示每个函数调用消耗了531 ns的CPU时间,112 B/op表示每个函数调用消耗了112字节的内存,3 allocs/op表示在每个函数调用期间发生了3次内存分配
从这个benchmark结果我们可以看到:
- 我们的Encrypt函数比另一个实现快了近20%,内存节省了16个字节
- 我们的Decrypt函数快了6%左右,内存消耗少了16个字节
这个时候我们就可以做决定了。
对一个接口的压测
这可能是最经常见到的压测形态了,用于这类压测的工具有很多,如:
- ab
- hey
- wrk
- dnsperf
等等,这类压测的特点是:
- 接口单一
- 对相同数据不敏感
如,我用hey压测了我的一个python应用的version接口,得到了如下的结果:
➜ pef git:(master) ✗ hey -n 100000 -c 200 http://127.0.0.1:19898/api/v1/version
Summary:
Total: 19.0831 secs
Slowest: 0.1048 secs
Fastest: 0.0003 secs
Average: 0.0372 secs
Requests/sec: 5240.2282
Total data: 1999960 bytes
Size/request: 20 bytes
...
从结果可以看到:
- 我们的服务每秒可以处理5240个请求,平均每个请求的响应时间为0.0372秒,最慢的请求花了0.1048秒
- 我们总共发了100000个请求,模拟了200个用户
需要注意的是:
- 测试数据对接口的影响需要明确,特别是对数据有校验和不同分支逻辑的情况
- 相同数据多次请求是否有缓存需要明确,避免得到与实际情况偏差过大的结果
- 对一些高性能的接口,需要考虑硬件的影响,看看是否达到了硬件瓶颈,如网口带宽等等
对一个简单服务的压测
真实世界的用户场景都是比较复杂的,是复合的场景。比如:
- 用户获取了设备指纹之后,再去验证滑动验证码
- 用户登陆后,浏览博客和论坛内容
这种情况下通过简单的一条命令就很难测试了,我们往往需要编写代码构造测试场景,从上古时期的loadrunner,到之后的jmeter,再到现在的locust之流,都是为了解决这类问题应运而生的。
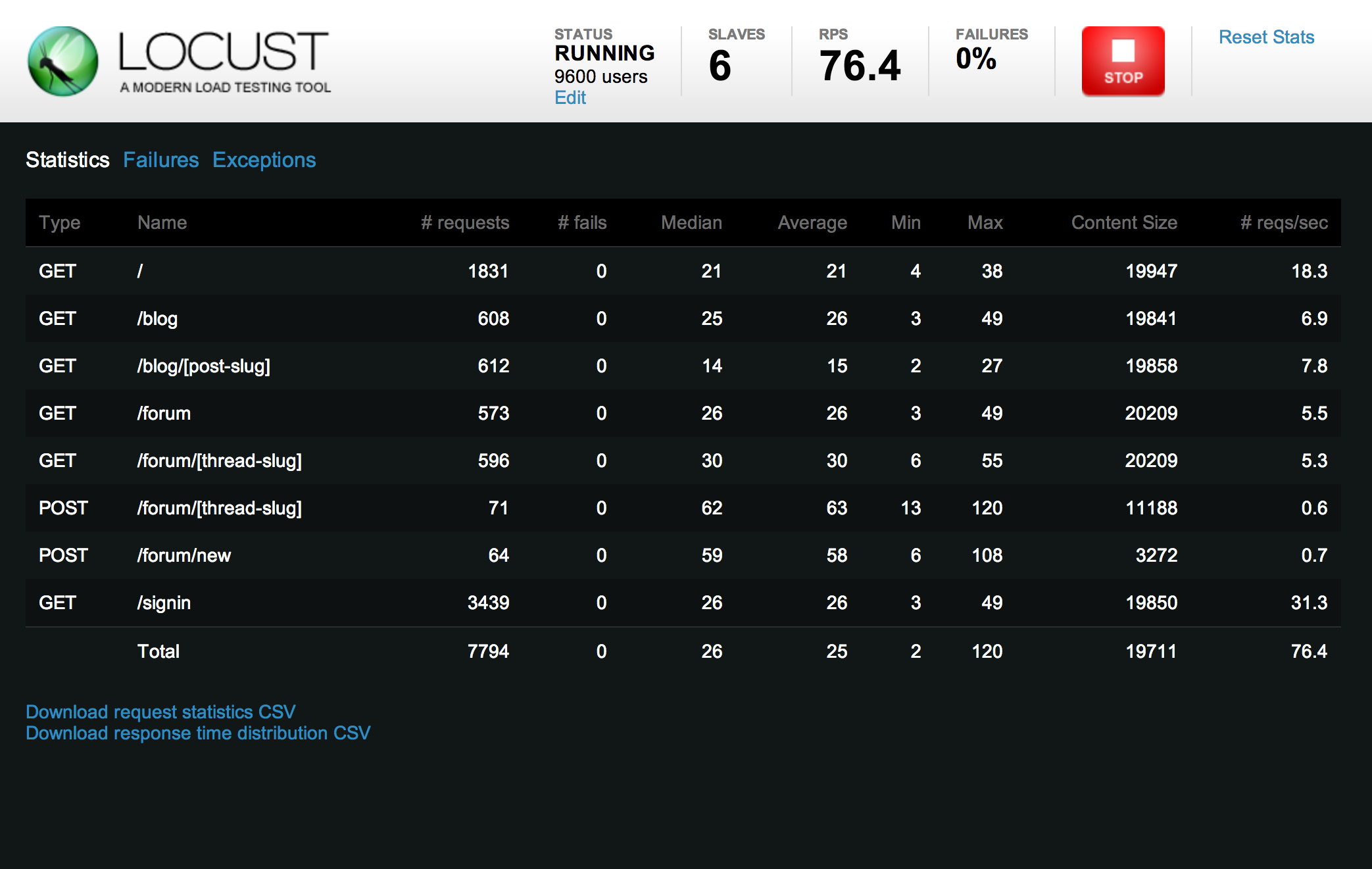
这类压测的特点是:
- 针对特定场景
- 存在一定的业务逻辑
- 数据有相关性
从locust官网抄了个例子下来:
from locust import HttpLocust, TaskSet, task
class WebsiteTasks(TaskSet):
def on_start(self):
self.client.post("/login", {
"username": "test_user",
"password": ""
})
@task
def index(self):
self.client.get("/")
@task
def about(self):
self.client.get("/about/")
class WebsiteUser(HttpLocust):
task_set = WebsiteTasks
min_wait = 5000
max_wait = 15000
这个例子中,每个虚拟用户会先进行login,然后按照比例访问主页和about页面,每个请求的间隔在5s到15s之间,从一定程度上保证虚拟用户尽可能地模拟真实用户的行为。
大型分布式系统的压测
当系统大到一定程度,上面的方法就行不通了,因为数据关联性太多,逻辑太复杂,导致几乎没有好的办法模拟。这个时候就得需要一些别的手段了。
常见的一个方法叫流量回放,就是把线上的流量按照一定比例放大,导入到测试系统中,然后观察测试系统的反应情况,有些服务能用这类办法,但也有不行的,比如涉及到P2P行为的系统就很难通过流量回放来模拟。
此时的方法概括起来有:
- 终端埋点
- 运维控制
- 数据采集
- 全景监控
终端埋点是指通过在网页、app等地方添加钩子,接收特定的指令来做一些事情,比如访问一个页面等等(很多基调公司就是这么做的)。
运维控制是指可以通过运维接口让特定的终端来参与到测试中来,进行模拟的页面访问等操作,这种方式让测试更贴近于真实。
数据采集是指通过一定的机制把这些测试数据都采集上来,包括终端的请求响应情况等等。
全景监控是指通过对采集的数据的汇总和可视化,达到对整个服务全景情况的监控目的,以获取压测结果。
压测工具的设计思路
设计一个像locust那样的压测工具,其核心理念与做一个高性能的应用是类似的,概括起来,基本功能包括:
- 组织场景
- 构造数据
- 模拟请求
- 采集数据
- 结果汇总
也就是说,能通过一些手段(如python脚本)把测试场景组织起来,构造测试数据,模拟HTTP(或其他协议)的请求,然后在工具层面采集数据,并将结果汇总展示。
除此之外,为了保证性能和可用性,往往还需要支持:
- 水平扩展
- 性能监控
- 分析结果
- 报表展示
水平扩展通常是一个master多个slave的模式,可以让多台机器参与压力测试,以避免因为施压机性能的问题而无法找出应用瓶颈。
性能监控是指除了获取QPS,响应时间这样的数据之外,我们通常还需要关注被测应用所在机器的CPU、内存、网络IO等数据,所以在压测时候需要同步收集这类数据。
分析结果对于收集到的数据进行预分析,提前过滤出可能的问题。
报表展示是对于测试情况能以图表的形式直观的展示。
从实现上来说,压测工具通常会:
- 读取测试脚本,编译为工具可识别的流程描述
- 把每个虚拟用户抽象为一个协程(或线程)按照测试脚本描述进行执行,每次执行完毕都会把结果汇报给压测工具的数据统计协程(或线程)
- 数据统计协程将所有虚拟用户的结果加以汇总,实时展示到报表界面上
- 报表界面在一个单独协程中,从统计协程消费数据,并通过某种方式(如web)加以展示
压测工具实现示例
在locust基础上实现了一个简单的压测工具,严格来说是slave端,它的具体思路如下:
- 复用locust的master端
- 基于locust golang sdk二次开发,解决locust性能不佳的问题
- 具体的业务逻辑在slave中实现,master只负责调度和汇总数据
大致架构如下图:
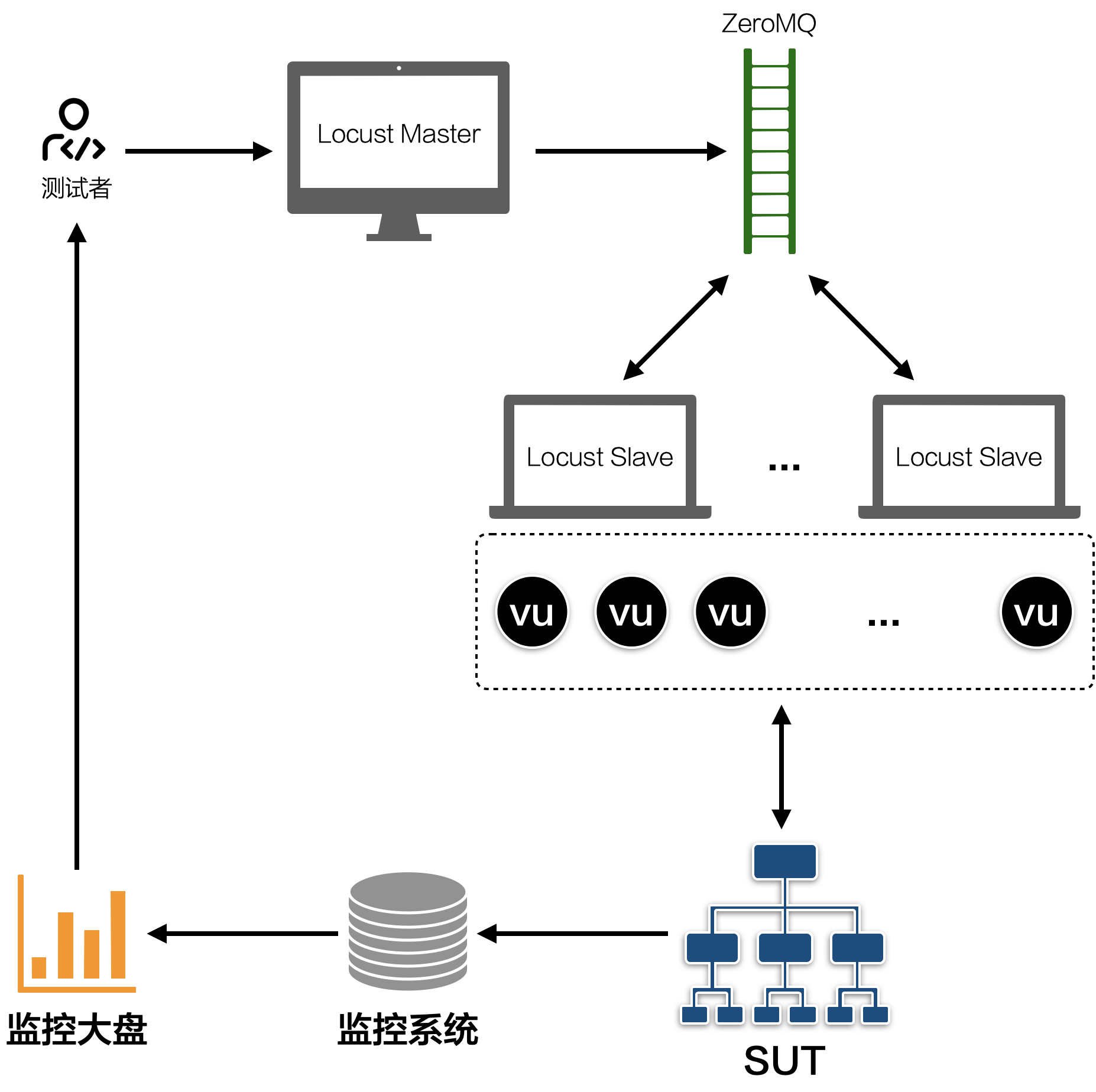
工作流程:
- Start master (locust)
- Start slave
- Loop:
- Master hatching
- Slave.OnStart()
- Slave running test, sync result to master
- Master show stats
- Master stop spawning
- Slave.OnStop()
- Stop Slave
- Stop Master
实现注意点:
- 对象池
- 连接复用
- Buffered Channel
这几个注意点基本都是为了性能考虑的,使用对象池减少GC,连接复用减少建连的开销,Buffered Channel让数据消费更顺畅(即不要用共享内存来通信,而是用通信来共享内存),同时能够解决掉一些高并发执行过程中的抖动问题。