从0到1构建DevOps系统
在DevOps从零到一中我们描述了一个应用的DevOps怎么开始,这一次,我们从DevOps系统构建者的角度,以一个具体的例子,来看一下一个DevOps系统是怎么逐步构建起来的。本文可以看作笔者之前在PyCon上分享的《从0开始快速构建DevOps系统》的细化版本。
问题的由来
某公司有一个私有化部署的产品,采用Java语言开发,涉及到多个服务和诸多中间件。当时遇到的挑战主要有以下几个:
- 包编不出来
- 不容易部署
- 质量不可观测
- 版本不可追溯
- 容量无法规划
- 线上问题多
问题一:包编不出来
很多人会对这个问题嗤之以鼻,难道本地编不通过就提交代码的吗?当然不是。 作为测试人员,可以说是这个产品的内部用户吧,我想要的是什么包?对于当时的我来说,想要的是整个产品最新的可发布的包,我希望实际体验一下当前这个产品。注意两个关键词:最新的、可发布的。我想从零开始编译和安装整个产品,这时候问题就来了。
- master上的代码太老了:在与团队同学交流中得知,团队使用类似Git-Flow的分支模式,master分支上永远指向最新可发布的代码。可是,实际使用下来,发现某些应用master分支已经很久没更新了。
- 对编译环境有依赖:尝试在一台新创建的虚拟机里编译应用,总是失败,而在专做编译的Jenkins机器上却没有问题。调查发现,某些依赖的包只在Jenkins机器的本地maven仓库存在,而一些二方库依赖使用snapshot版本,对应代码与之前不兼容,导致本地新编译不通过。
- 编译过程缺乏描述:某些应用在编译前需要下载一些二进制文件,执行额外的步骤,这些过程没有明确定义下来。
问题二:不容易部署
该产品使用容器镜像作为打包方式,理论上说,安装部署过程应该非常顺利。但实际执行下来,还是遇到了很多问题,经常遇到部署失败的问题。这些问题背后的原因很有普遍性,我总结一下。
- 应用启动顺序有依赖:某些应用依赖其它应用启动后才能提供服务,而如果顺序有错误,并没有直观的错误提示出来。
- 镜像里缺失某些文件:单纯拿到镜像,并不能把某些应用启动起来,还需要一些其他文件,并将这些文件mount到容器中才能正确启动。
- 配置项太多:应用启动时依赖配置文件,而配置文件中存在很多配置项,一不小心改错了某些配置,就会出现部署问题。
- 部署过程靠文档:整个部署过程依赖文档,缺少必要的工具支撑,部署完成后,也依靠人工验证,很容易造成部署问题遗漏。
问题三:质量不可观测
我们的产品质量当前处于什么水平?有没有度量数据?这可能是一个测试架构师在进行工作计划的时候经常提的问题之一。然而,这类数据在当前很多初创公司都很难拿到。大家会很快地交付产品,然后很快的响应客户的问题,但交付的质量由于是隐性的,经常被有意无意地忽略了。与之相关的,质量上的实践也经常会处于比较靠后的优先级。比如:
- 单元测试没有或跑不起来:很多应用没有单元测试,有的即便有,但由于缺乏维护,跑不起来。
- 自动化测试几乎没有:功能验收大都靠纯手工,自动化测试建设很少。
- 代码提交缺少卡点:除了对master等分支限制直接提交外,其它像Code Review、代码规约、代码质量检测、自动化测试等卡点几乎没有。
- 外部问题缺少管理与分析:遇到外部问题并解决后,缺少后续的步骤,比如添加单元测试等,对于问题也没有很好的管理。
问题四:版本不可追溯
对于私有化部署的产品,版本升级的权利掌握在客户那里,因此长期维护多个版本就成为不可避免的问题,尤其是客户遇到问题需要进行缺陷修复的时候。我一开始认为客户将问题告诉我们,附上对应的产品版本号,我们修复之后,将更新的包发给客户部署验证就可以了。可是,这里有一个前提:产品有版本号,并且产品版本号可以和各个应用的代码版本对应起来。遗憾的是,当时并没有这个对应关系,这样修复问题的风险就很大了。
问题五:容量无法规划
这个不是简单的没有性能测试的问题,事实上,对于该产品的性能测试一直都在做。但是我们无法正确识别用户的场景,从而给出这种场景下的基线数据。这里面有有两个问题:
- 缺少基于场景的测试:针对某个接口的功能测试和压测往往是不够的,我们需要抽象出用户的使用场景进行测试,才能确保交付质量。
- 缺少类客户场景下的压测数据:比如基础数据量,请求的流量模型,业务配置等,由于某些关键服务存在容量限制(比如内存),就非常依赖这种基于真实用户使用场景的压测数据。当然,如果有方便的容量伸缩手段,也会好很多。
问题六:线上问题多
这个是质量问题最直接的结果,和对质量进行投资最直接的原因。但是,用户问题其实可以分为两类的,一类是真正的软件缺陷,另一类是设计上的不友好。笔者曾经对接过一个SaaS服务,接口参数多达近百个,且里面很多参数都是布尔型的开关参数。最后,笔者是求助于该公司的开发同事才得以正确调用该接口的,这个服务接口在设计上对使用者就极为不友好。
小结
说明:该公司在人员组成上没有专门的运维和测试同学。很多时候,这是一个优点,每个研发都应该关注质量和交付,而不仅仅是编码。但在具体实践上,由于缺乏有效的规范和工程手段,导致从研发到交付的过程比较混乱和低效。
另外,成员大都来自于互联网公司,缺乏版本制私有化交付的经验,在版本管理和交付实践上问题较多。
第三,组织结构上职能团队的划分方式,缺乏一个整体视角来关注研发效率,客观上也影响了交付效率。
从部署开始
在对问题梳理之后,我们可以发现,该团队从开发到交付,效率是逐渐降低,风险是逐渐升高的。这也意味着产品交付的越多,团队在后期运维上花费的成本会越高,交付客户需求的能力也越低。

熟悉DevOps或CI/CD的同学都会想到一堆要解决的点,比如分支规范、自动化测试、代码审查卡点等等。面对一个快速发展的互联网公司,从哪一个点开始呢?
笔者是以部署,确切地说是自动化部署作为切入点开始着手解决这些问题的。为什么从部署切入呢?原因有二:
- 部署涉及到的人最多
- 实现简单,能快速看到效果
对于第一个原因,其实也是笔者推行的原则——让更多的人更早用起来。见下图,与部署直接相关的人包括几乎所有一线的产品研发和实施工程师,包括前后端程序员、部署实施工程师等,同时,周边团队如产品、UED、AI团队也会间接与部署产生关系。这么一来,几乎整个研发团队都直接和间接地影响到了。
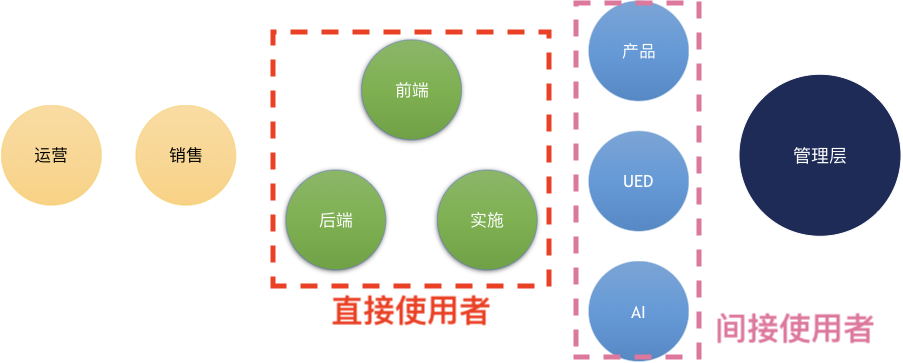
而由于使用部署的人这么多,使用这么频繁,因此改进带来的收益也就更大。而看到收益之后,也更容易得到管理层的支持。
对于第二点,简单的系统意味着学习成本低且稳定,而通过大量真实用户的使用,很容易积累出真正的需求,从而让系统不至于变得庞杂,让使用者不知所踪。
部署-phase 1:一个python脚本
于是第一版的部署工具就以一个简单的脚本形式出现了,使用起来就一条命令:
python -m devops.tools deploy_docker -h env-1.test.local -u demo -p Demo123 -c harbor/c1:v1 -c harbor/c2:v2
笔者在内部所有测试服务器上安装了这个脚本,这样任何人想在测试机器上部署环境,只需要在任意一台服务器上执行这个脚本就可以了。
它的实现非常简单,看起来就像下面这段fabric进行远程服务器操作的小脚本:
import click
from fabric import Connection, Config
@click.command('deploy_docker')
@click.option('--host', '-h', required=True, help='host to deploy')
@click.option('--user', '-u', default='test', help='username of SSH login')
@click.option('--password', '-p', default='test123', help='password of SSH login')
@click.option('--component', '-c', multiple=True, required=True, callback=_validate_app)
def deploy(host, user, password, version, component):
config = Config(overrides={'sudo': {'password': password}})
with Connection(host, user, config=config, connect_kwargs={'password': password}) as conn:
for app_item in component:
click.echo(f'start to deploy {app_item.image}:{app_item.version}')
_do_deploy(conn, app_item)
# _do_deploy ...
部署已经构建出来的应用,用这个脚本简单了很多,将之前大量对着文档的手工工作,简化成了一条命令。但是对于正在开发中的应用呢?开发中间频繁的联调才是部署使用的大户,而目前这类需求无法被满足。
为部署作准备
出于提升联调部署效率的目的(也可以说是打着提升部署效率的旗号),笔者开始进行工程实践标准的制定。事实上,标准的制定和推行与DevOps系统(好吧,之前那个简陋的小脚本我作为DevOps系统的0.01版)的演进是同步进行的。换句话说,标准与工具相辅相成。
总共包含四个标准:
- 标准化持续集成
- 标准化构建
- 版本规范
- 分支规范
标准化持续集成
为了保证应用代码基线的质量,同时让通过基线验证的代码能尽快被部署,每一次git push都应该被构建(和验证)。
针对这一点,我们引入了gitlab-ci,通过代码中的.gitlab-ci.yml来定义持续集成的流程。对于持续集成,我们做了如下约定:
- 镜像的构建只依赖于项目中的Dockerfile文件
- 开发分支的代码必须经过自动化测试
- 持续集成的目标是经过验证的镜像被发到镜像仓库中
以一个.gitlab-ci.yml为例:
variables:
QS: "namespace=${CI_PROJECT_NAMESPACE}&project=${CI_PROJECT_NAME}&branch=${CI_COMMIT_REF_NAME}"
before_script:
- curl -s -o cci.sh --retry 5 http://tao.test.local/api/v1/cci/script\?${QS}
- source ./cci.sh
stages:
- build
- package
- test
- deploy
# stage definitions
# ...
这个例子在before_script里面定义了一个获取cci.sh脚本并source的步骤,其目的是为了对所有项目的CI流程进行能力复用。通过在cci.sh里面定义环境变量和函数的方式,达到更新CI步骤不需要逐个更新应用的目的。之所以用这个方式,是因为当时的gitlab-ce版本不支持在.gitlab-ci.yml中引用template,如果这个问题已经解决,则template是更优雅的一种方式。
另一方面,为避免代码合并带来的验证缺失风险,我们对代码合并做了约束,要求合并方式必须为“Merge commit with semi-linear history”或“Fast-forward merge”,gitlab上的配置如下图:
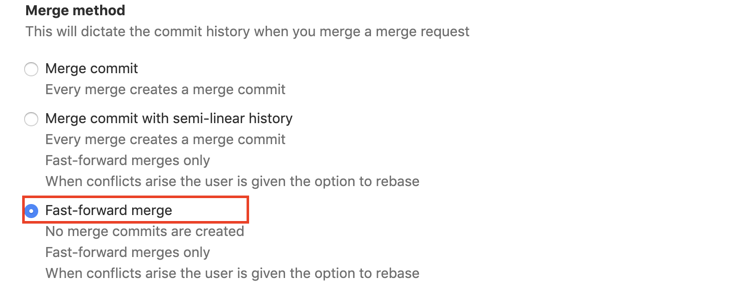
这两个设置的本质是保证,当一个分支A合并到另一个分支B前,A分支包含了B分支所有的commit。也就是说合并完成后,A分支的代码与B分支的代码是一致的,这样做就保证了在A分支上通过了持续集成,合并之后不再需要重复进行验证,因为代码基线相同。
而“Merge commit with semi-linear history”与“Fast-forward merge”的区别在于,前者会创建一个merge commit,方便追踪和回退;后者则类似rebase,所有commit都是线性的。
标准化构建
在标准化持续集成中我们已经定义了构建的目标是docker镜像,构建的流程在.gitlab-ci.yml中描述,那么,作为标准化构建,还缺什么呢?
主要有两方面:
- 应用配置
- 环境描述
我们可以想一下构建的目标是什么,所谓构建,是将源代码变成可运行的程序的过程。而构建出来的程序,在其生命周期里,有两个主要的使用场景:一是测试、二是运维。这两种场景,都离不开一个必要的步骤——部署。而对于部署来说,让一个应用能跑起来并且提供服务,有两个必备条件:应用配置、依赖环境。
标准化构建就是来解决这两个问题的。
我们通过两个实践来解决应用配置的问题:
- 配置代码化 也就是所谓的Infrastructure as Code,我们建议配置与代码、测试用例保存在同一个git repo中,构建的时候静态配置直接打到镜像中。这么做的好处是维护简单,坏处是即便只改了配置,镜像也会重新构建,同时配置和代码的权限绑定在一起了。但是对于该产品的私有化交付形态来说,这些不是主要问题。
- 环境DNS描述 私有化部署的需求,加上不同测试环境的需要,在环境运维上引入了一个简单的DNS服务,同时要求配置文件去IP,各种环境都采用相同的DNS域名来定义。这样就把之前每次部署都需要修改配置文件相关IP地址的工作,统一到DNS的配置上。这类DNS服务可以很简单的实现,参照我写的一个示例应用udns。
环境问题包含三个方面:
- 测试环境资源的复用
- 测试环境的隔离
- 应用的运行依赖
测试环境是使用最频繁的一类环境,如果每个开发需求在测试的时候都需要从零构建一整套测试环境,无论在时间上,还是资源消耗上,都是极为不经济的。所以,这里我们需要对环境中的应用和各类组件做下分层,例如:
应用: component-a | component-b | ...
-------------------------------------------------------------------
环境独立组件: cacheXXX | Queue | ...
-------------------------------------------------------------------
环境共享组件: DB | HDFS | ...
对于应用,我们采用的是每个测试环境部署一份的做法,也就是说,在不同环境之间应用都是隔离的。当然,大厂一般会引入环境标签,在这一层也会做复用。关于这一点,笔者以为,在中间件里面做环境标签的方法局限性比较大,类似istio这样的service mesh方案会是将来的趋势。
另外,某些会产生冲突但又不方便分区的组件,如存储session的缓存等,也采用每个测试环境部署一份的做法。
剩下的,像数据库、大数据存储等资源消耗大户,则尽量进行复用。最后达到一台虚拟机可以部署一套环境(不含共享组件)的目的。
版本规范
针对私有化交付的特点,我们交付的是产品的某个版本。这其中包含应用、配置、数据等多个内容,而每一块也有其自己的版本,最终对应到代码版本。换句话说,我们需要建立产品、模块、代码三者之间的版本关系。于是乎,我们建立了一套版本规范,来约定这些内容。
如交付的产品名为“监控系统”,当我们说交付“监控系统v1.1.0”版本时,深入到版本详情,我们可以知道,交付的具体内容为:
- ops v1.1.0
- sql v1.0.0
- testcase v1.1.0
- graph v1.0.2
- agent v1.1.0
- api v1.1.0
- self-monitor v1.0.3
而类似ops v1.1.0对应于ops这个git repo的v1.1.0的tag,这样就与代码版本对应了起来,解决了追溯的问题。
最近,阿里云和微软联合推出了OAM的模型,某种程度上在云原生的范畴定义和明确了这个问题,当然,这个模型有更大的愿景,感兴趣的可以访问oam.dev。
分支规范
版本规范解决了交付的标准和追溯问题,分支规范要解决的是研发协同的问题。当我们发现研发中间经常出现冲突,新版本开发期间需要修改老版本的bug却不知道在哪修改时,我们就该考虑分支规范的问题了。
本文不打算展开介绍分支规范的各种细节,只以该产品和团队为例,聊一下选择的分支规范及其背后的考量。
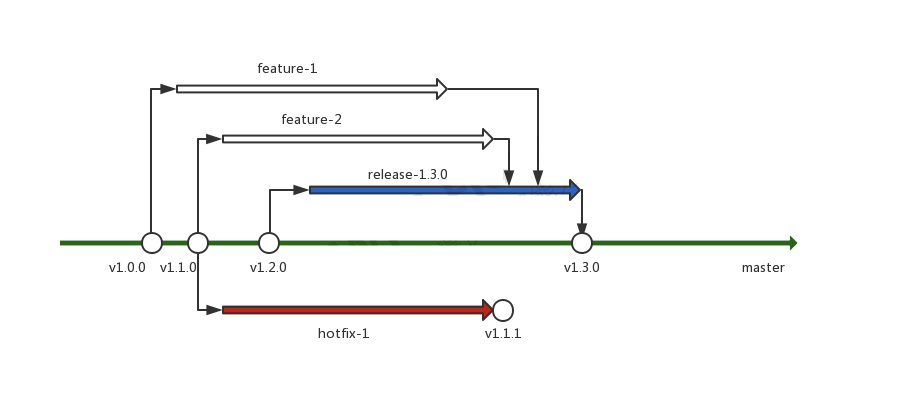
上图为该产品和团队的分支规范,简单说明如下:
- master分支为唯一的主干,同时也为唯一的长期分支,不允许直接提交
- 每个需求开发都从master分支创建feature分支
- 每个发布周期都从master分支创建release分支
- feature分支合并到release分支进行集成测试,发布时合并到master分支,并打tag
- 历史版本的缺陷修复从对应的tag拉取hotfix分支,修改完成后,直接在hotfix分支上打tag
- feature/release/hotfix分支在合并或打tag后即被删除
我们知道,如果发布很快(每天数次),同一应用很少被同时修改,是不需要定义分支规范的,直接在master上提交、测试、发布就可以了。那我们为什么要不嫌其烦地定义一套上面那样的分支规范呢?
原因有这几个方面:
- 同一个应用往往有多个需求在并行开发,互相之间发布节奏不同,也需要避免冲突,所以有了feature分支
- 私有化的应用版本升级由客户决定,因此对于已发布版本有长期维护的需求,不能只维护最新的版本,所以有了tag和hotfix分支
- 测试周期和发布周期比较长,一个版本的开发发布持续1个月,这中间会有频繁地开发和修复需求,所以有了release分支
- 发布周期需要保持稳定,如果赶不上发布周期,宁可少上需求,也要维持发布节奏,所以release分支不能是长期固定分支
至此,我们可以看出,分支规范在设计时考虑了发布节奏、发布形式、并发协作、研发效率等多个因素,在可选的情况下,我们应该倾向于更简单的规范如TBD(Trunk Based Development),当然这中间离不开高效测试自动化等最佳实践。
部署-phase 2:web部署工具
在做上面这些标准化工作的同时,我们的第二版部署工具逐渐成形了。回顾第一版的部署工具,我们觉得它实在太过简陋了,更重要的是,它没有把我们定义的这些标准和规范内建到工具中。
一个好的标准和流程,只要内建到工具中,在日常工作中切实帮助开发者解决问题,才能得到大家的支持并产生价值。所以,在标准逐渐确定的过程中,我们及时把这些标准融入到第二版的部署工具中。
先看一个最常用的例子:
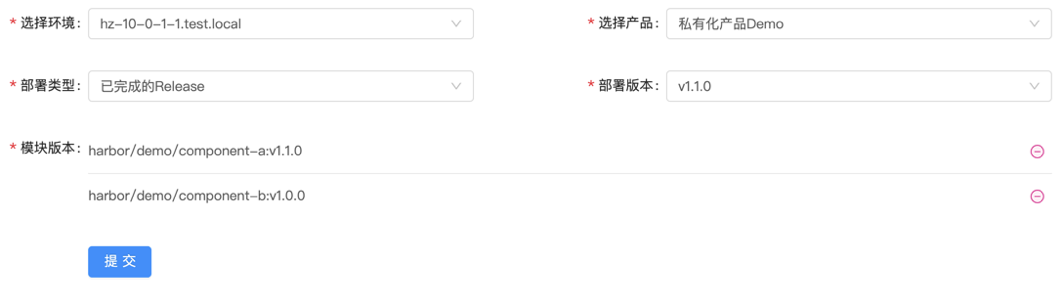
这是一键部署某个产品版本到特定环境上的例子,在这个例子中,有几个要素:
- 环境
- 产品
- 产品版本
- 模块
- 模块版本
同时,又有几大关系:
- 产品与模块之间的关系
- 产品版本与模块版本之间的关系
- 产品版本与环境之间的关系
这些要素与关系都是部署工具需要去处理与保存的,这也是它的核心模型与价值所在。
上面的部署任务提交后,会自动调度一个任务去执行,而执行的脚本就是我们phase 1所编写的那个。所以,本质来说,phase 2只是在phase 1的基础上扩展了要素与关系。
任务示例见下图:
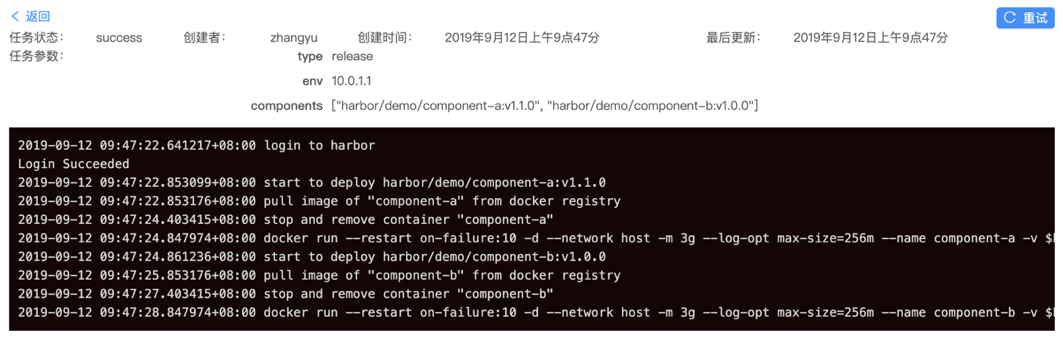
phase 2:具体实现
由于引入了前端和存储,这时的工具跟普通的Web应用长得很像了。
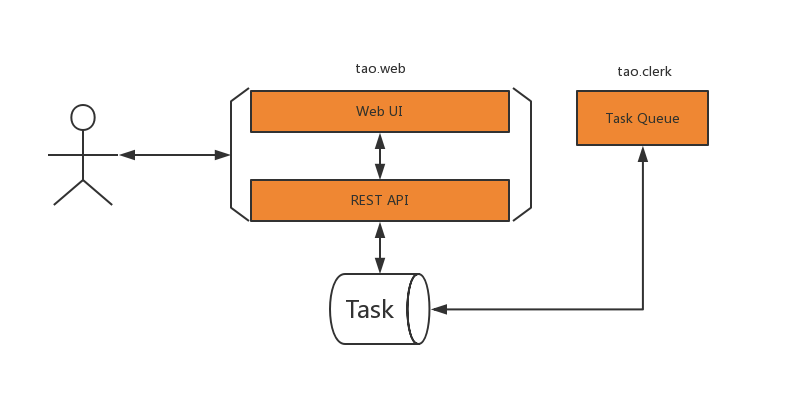
- 通过Task表保存待执行任务
- 有tao.clerk模块专门负责Task的执行和处理
- 具体的工作有tao.tools负责,最大程度复用了phase 1的脚本
考虑部署简单和团队实际情况,实现采用了supervisor起多进程这种反容器模式的做法。
supervisord
|
|- tao.web (sanic + motor + pymongo)
|
|- tao.clerk (asyncio + motor + pymongo)
将web和clerk独立为两个进程,将来团队扩大的时候,可以方便地水平扩展。而如果部署环境k8s化,也很容易拆成两个容器。因此,将来的改造成本很低,现在用起来很方便,于是就反模式喽。
在clerk的Task runner实现上,笔者也尽量从简,没有引入额外的框架,直接用asyncio写了个while循环,主要代码如下:
import asyncio
from tao.models import Task
from .runner import TaskRunner
_available_workers = asyncio.Semaphore(5) # max 5 concurrent tasks
async def load_task_queue():
while True:
task = await Task.find_one_and_update({'status': Task.WAITING}, {
'$set': {'status': Task.RUNNING}})
if not task:
await asyncio.sleep(2)
continue
asyncio.get_event_loop().create_task(_run_task(task))
async def _run_task(task):
async with _available_workers:
logging.debug(f'schedule task "{task}"')
await TaskRunner.run(task)
部署:小结
至此,部署的事情告一段落,从开始到标准化改造完成和phase 2落地,历时2个月的时间。 这一阶段工作的受益者是一线的开发和测试同学,他们每天都在用这个工具,自然而然地把一些标准实践了下去。从实践来说,这一阶段更多的是建立标准,进行自动化,相对来说容易完成。柿子捡软的捏,部署的落地给后续的工作开了个好头。
接下来要做的事情,跟很多公司在做的敏捷转型,在实践上就有很多相通之处了。无论是DevOps还是敏捷,其最终的目的都是要提升需求交付效率,更快地实现用户价值。
让数据互通:研发数据是有联系的
所谓研发数据,包括多个方面,如需求、缺陷数据,代码提交、评审数据,测试执行和结果数据,运维故障和风险数据等。
问题:私有化应用如何做OPS?
从事过电信产品研发的同学都知道,电信应用是典型的私有化部署方式。为了提高应用的运维能力,电信设备商会通过OAM系统提供大量的运维支持。同时,也会做好充分的系统测试来应对可能发生的故障和风险。原因无他,出错成本太高了!
因此,私有化应用的OPS是必须做而且应该认真做的。这里面有两个要点:
- 假装自己是客户
- 快速发现、快速反馈
假装自己是客户,私有化应用必须经过系统测试,系统测试的时候,必须站在用户的视角来定义场景和验收。 因此,用户的业务场景和使用方式是我们需要重点关注的,尤其是各类异常情况。毕竟我们不能总是说应用出问题是你用得不对。 在实践上,我们部署了一套内部试用环境,每次版本发布,都会升级这套环境,而升级使用的流程和工具跟在客户现场升级保持一致。同时,内部的各种角色,包括产品、营销、技术团队,平时都用这个环境进行各类场景演示和体验,遇到问题,及时提交缺陷。
快速发现、快速反馈,监控是系统的双眼,做好监控,让问题快速地暴露出来。很多ToC背景的团队开始做私有化的ToB的业务时,也习惯于快速地做客户看得着用得到的业务,而把运维系统、监控系统放到比较后的位置,甚至不作考虑,这是有问题的。ToB业务尤其是私有化的ToB业务,要在迭代中保持用户使用习惯的稳定,系统性能和稳定性的提升,比功能上的增加更重要。
客户的反馈和需求是我们最好的OPS来源。快速反馈,减少在制品,是来自精益企业的思想,通过减少等待提升整体效能。客户的反馈从提出到解决的周期应该要做到尽可能短。类似普通线上应用在收到故障告警到问题修复,要越快越好。
接下来,我们可以引导客户把监控发现的问题脱敏后发送给售后同学。试用环境遇到的问题和客户反馈作为需求或缺陷统一地保存和管理起来。这些数据会是我们非常宝贵的资产。
定义数据的边界
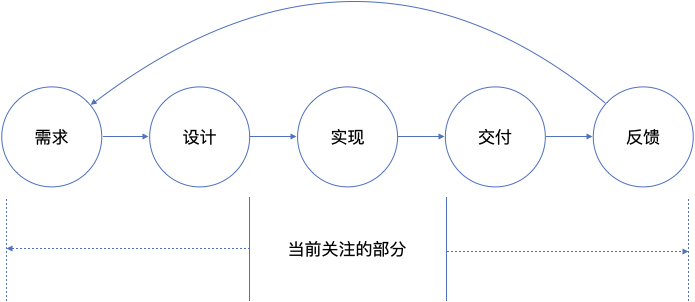
- 如上图,在上一章从部署开始我们构建了从开始开发到准备发布的完整流程,我们把这个过程中的数据称为研发数据。
- 而从需求被提出开始到开始开发前,这里的主体是需求(包括子需求)和缺陷。我们把这类数据称为需求数据。
- 另一头,从发布开始到系统在用户现场运行期间产生的数据,我们称之为运维数据。
三个数据有各自的流程边界,同时又相互关联,形成完整的DevOps数据集。
研发数据
在上面的实现方案中,我们的研发行为都是通过GitLab及GitLab-CI的pipeline串联起来的。我们能从中获得哪些数据呢?
- commit
- pipeline
- test
- code review
- code quality
而从pipeline中继续挖掘,我们又能得到需求开发效率和发布的数据。
看起来很美好,可惜这些数据太零散了,看不到全貌,也不方便实时获取。因此,我们的办法是保存一张event表,将发生在gitlab上的所有事件都记录下来,同时,根据事件的不同类型,通过handler进行处理,建立起数据间的相互关系。实现上非常简单,我们借助GitLab的webhook能力,实现了一个webhook接口,接入所有相关的git项目。这个接口通过sanic实现的代码简化如下:
@gitlab_bp.post('/api/v1/gitlab/webhook')
async def gitlab_webhook(request):
event_name = request.headers.get('X-Gitlab-Event')
token = request.headers.get('X-Gitlab-Token')
event = request.json
await GitlabEvent.create(event) # 记录gitlab事件
await WebHookHandlers.on_event(event_name, event) # 事件的实时处理,如发送通知、触发依赖项目等
需求数据
该公司采用腾讯提供的TAPD作为项目管理工具,管理项目、迭代、需求和缺陷数据。这些数据可以归为需求和协作域,而另一边,研发域的数据则几乎都在GitLab中,显然,有必要建立两者的关系。笔者在编写这段代码的时候,TAPD还没有提供WebHook的功能,因此我们没法像获取GitLab数据那样,通过定义一个hook interface来实现。
TAPD提供了各类资源的API,我们通过定时的scheduler来同步相关数据。为了确保两边的一致性,我们做了几个假设:
| 销售和产品 | 研发和实施 |
|---|---|
| 产品 | 项目(TAPD) |
| 发布 | 迭代(TAPD) |
| 版本号 | 迭代名(TAPD) |
同步的代码大致如下:
async def sync_stories_from_tapd(product):
workspace_id = product['tapd_workspace_id']
# ...
async for story in TAPDProxy.get_stories(workspace_id):
logging.debug(f'sync story "{story["name"]}({story["id"]})"')
await TAPDStory.find_one_and_update(
{'id': story['id']},
{'$set': story},
upsert=True)
# ...
运维数据
客户反馈和监控系统发现的问题,按流程统一录入需求或缺陷,通过特殊的Tag区分。之后,进入正常的迭代和研发流程。
小结
数据是指导企业活动的重要资产,我们通过定义数据、收集数据、联系数据这三个步骤,初步建立起DevOps的数据模型。至此,我们可以很方便地进行需求开发的规划和研发活动的追踪。
我们假设一个特性总是一个可以独立交付、有价值的最小单元。一个特性会对应一到多个记录在TAPD上的需求和缺陷,这些信息会在开始开发前由开发人员确认,这样,相关的信息就可以及时同步给需求和缺陷的关注者,如产品、交付人员。
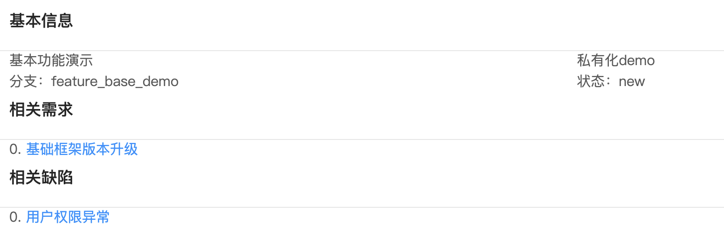
开始开发后,相关的开发信息,如与之相关的模块,最新持续集成的状态等,也都会汇总到看板上,方便特性开发相关的人员查看。
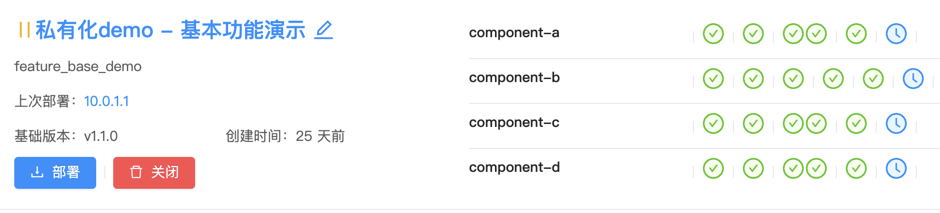
而作为一个迭代,则有一个版本号,且包含多个特性交付,因此,这些信息都会汇总到迭代的看板上。
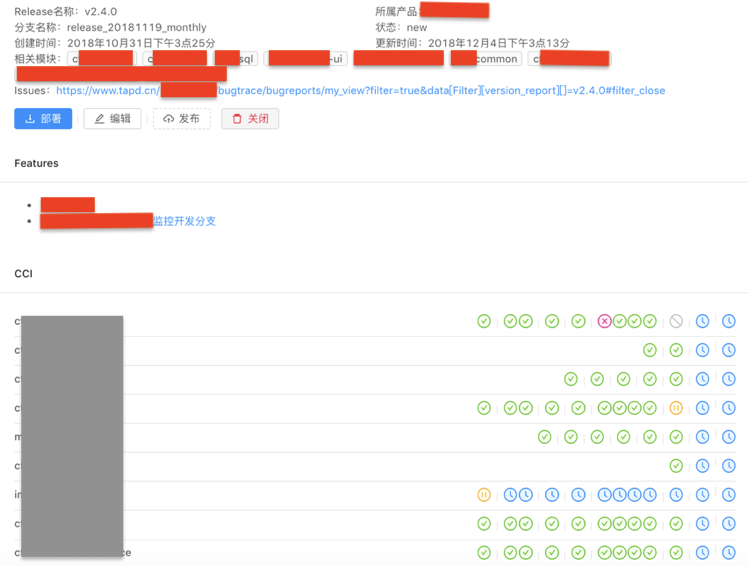
让数据可见
至此,我们在数据上将DevOps各个阶段联结在了一起,同时,在工具上,通过定义产品(Product)、模块(Component)、特性(Feature)和发布(Release),做到了研发协同。
接下来,我们需要回答一个经典的问题:团队的研发效能怎么样?通过数据可视化和数据分析,我们试图给这个问题一些参考。
在这个例子中,我没有对这个问题做很深入的分析,一些简单的思考和实践,权作分享。
指导原则与实现方向
直接抛出原则:关注整体,远离KPI。
针对具体的数据设定KPI,我认为是研发效能改进最大的反模式。只有关注整体,直面根本性的问题如交付效率,通过对效率和质量的关注来引导团队逐步改进,才能真正达到提升效能的目的。否则,面向KPI的改进,最终只能是事与愿违。
在实现上,方向非常简单:关注数据接口,展示交给grafana。
这不仅仅是避免过多的研发开销。将数据与展示分离,能够迫使开发者提供相对通用的数据接口,把展示方式和关注的重点交给具体团队的同学,让他们可以根据自己的实际情况选择需要关注的指标,从而更好地为自己负责。
如果只有一张图
如果只能放一张图,我们选择累积流图。
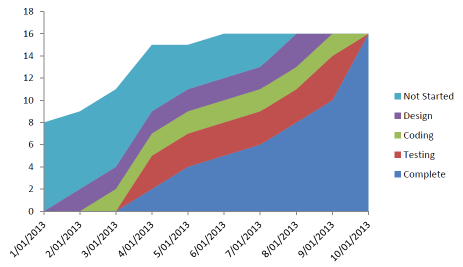
累积流图信息非常丰富,除了可以看到我们每个阶段的完成情况,还可以看到我们的工作方式,是否产生堆积,交付效率在上升还是在下降。但为了保证数据客观有效,切记不要设KPI。
对接grafana
我这里偷了个懒,将数据伪装成falcon-plus的格式,接入grafana。之所以这么做,是因为我在基础监控的时候已经有了falcon-plus,且搭建了grafana,这里直接就复用了。
以falcon-plus的格式对接grafana只需要实现两个接口就可以了,他们是:
GET /api/v1/grafana/metrics/find (交互)
这个接口用于设置查询参数,如选择应用,版本号等,如下图:
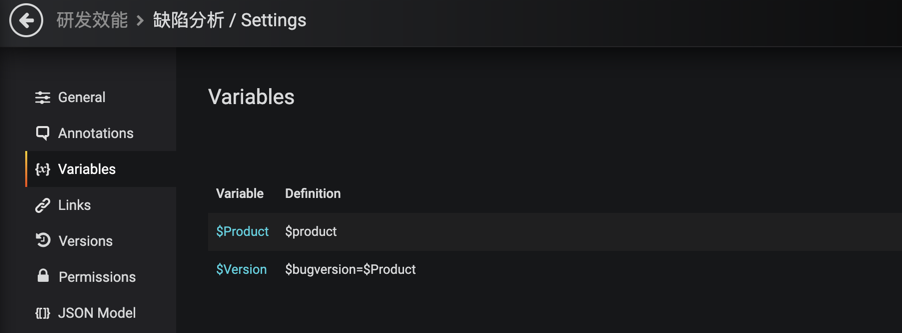
其实际是通过如下的配置来调用查询的:
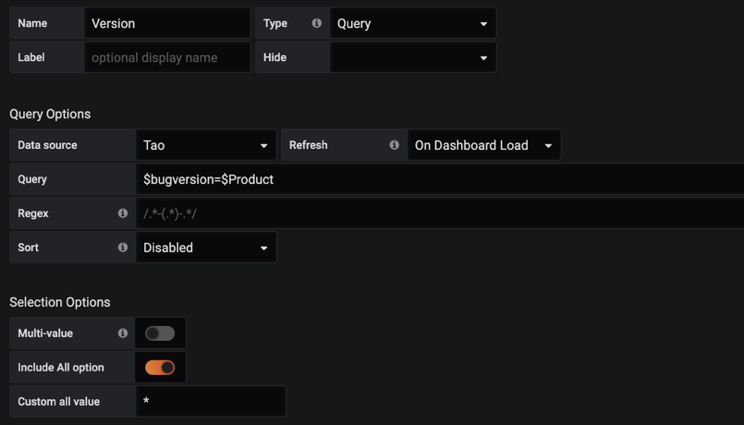
最后,通过调用对应的函数,来进行查询。
class _TagQuery(object):
# tag query functions
@_tag('product')
async def query_products(self, q):
return await Product.distinct('name')
@_tag('component')
async def query_components(self, q): # q is product name
if q and q != '*':
return [c['components']['name'] async for c in Product.aggregate([
{'$match': {'name': q}},
{'$lookup': {'from': 'component', 'localField': 'components', 'foreignField': '_id', 'as': 'components'}},
{'$project': {'components.name': True, '_id': False}},
{'$unwind': '$components'},
])]
return await Component.distinct('name')
POST /api/v1/grafana/render (展示)
这个接口用于获取具体的展示数据,交给grafana渲染成图表,示例如下:
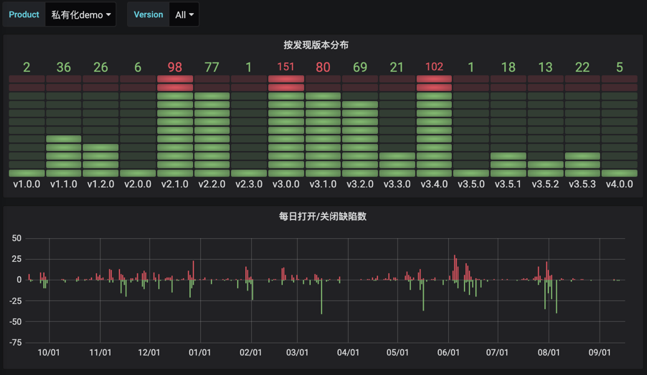
其对应的函数实现为:
class TapdMetrics(AbstractMetrics):
ENDPOINT = '@tapd'
@metric('product.version.bugs')
async def bugs_count_by_version(self, params):
filter_ = await self._parse_common_params(params)
if filter_ is None:
return []
return [
self.build_falcon_record(
[{'value': item['count']}],
endpoint=item['version'] or 'N/A',
step=_1DAY
) async for item in TAPDBug.aggregate([
{'$match': filter_},
{'$group': {'_id': '$version_report', 'count': {'$sum': 1}}},
{'$project': {'_id': False, 'version': '$_id', 'count': True}}
])
]
改造falcon-plus
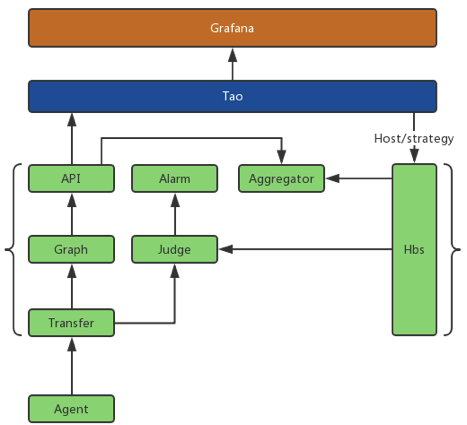
上图是改造后的falcon-plus简单架构图,这里简要说明一下改造的部分。
| 模块 | 功能 |
|---|---|
| hbs | 为agent等模块提供rpc调用,用于同步tao上的相关配置等信息,是falcon从tao获取数据的唯一接口 |
| api | 对外提供HTTP查询服务的唯一接口,但不直接提供给grafana,而是通过tao代理 |
| 通用 | 去除falcon-plus中的监控资源、监控配置等所有定义部分,这部分数据改为通过hbs从tao获取 |
这样,falcon-plus的功能就更为单纯,将监控策略等信息都外置到tao这样的运维系统,方便管理,也便于升级。
提供pandas友好的数据查询接口
虽然grafana在使用上足够通用、灵活,但是,还是会存在需要拉取数据进行自定义分析的场景,比如对于缺陷数据通过算法进行聚类。这时候,一个灵活但友好的接口就非常方便了。
针对这类需求,我们对重要的数据都设计了pandas友好的查询接口,其支持定义获取的字段和查询接口,同时能通过iterator的方式按行以JSON格式返回数据,免去客户端分页请求的烦恼。
使用举例如下:
# GET /api/v1/tapd/bugs?workspace_id=12345678&fields=id,status
import ujson
import requests
import pandas as pd
def _read_bugs(workspace_id):
return requests.get(
'http://tao.local/api/v1/tapd/bugs',
{'workspace_id': workspace_id, 'fields': 'id,status'}
).iter_lines()
bugs = pd.DataFrame((ujson.loads(line) for line in _read_bugs('12345678')))
# return value
# {"id":"10001","status":"closed"}
# {"id":"10002","status":"closed"}
# {"id":"10003","status":"closed"}
# {"id":"10004","status":"closed"}
# {"id":"10005","status":"closed"}
# {"id":"10006","status":"closed"}
# {"d":"10007","status":"closed"}
总结
最后,让我们来看一下整个系统长什么样。
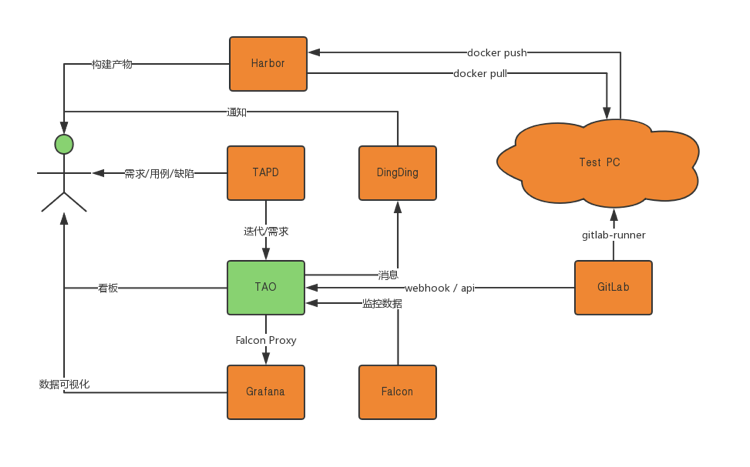
Tao这个工具最后包含6340行Python代码和6386行JavaScript代码,共有1096次commits,打了263个Tag,相当于每天都有一次发布。
而在同时,Tao支撑了研发团队2663次部署,以及157次版本发布。
从工具的角度讲,它以极小的代价,很好地支撑了团队的DevOps需求和研发效能提升。
让我用一张图来结束吧。
