DevOps从零到一
CI/CD,以及DevOps早就不是一个新的概念,但是如果你仔细观察,会发现有相当多的公司,在DevOps上还处于非常低的水准。造成这种现象的原因很多,如管理层缺少软件工程的概念,组织结构存在隔离,缺少合适的工程实践人员等等。
实际上,如果考虑投入/产出比,可能没有比搭建一套DevOps系统对一个软件开发项目的效率提升更大了。很多时候,一个简单的集成、部署工具就能为团队每天节省好几个小时的时间。
但是,对很多团队来说,DevOps是一个相对陌生的东西,有些人觉得DevOps就是维护Jenkins和其上的一堆Job,有些人觉得就是一个把产品放到线上去的脚本,总之,这个事情看起来是一堆的搭建、配置、维护这样的脏活累活,很繁琐,好像也没啥技术含量,做得不好还容易遭埋怨。另外,在大多数小团队里,几乎是清一色的开发人员(甚至确定到Java开发人员这样的组成),而在大家的认知里,DevOps这件事应该是运维工程师来做的,我只要写好业务代码就行了。这种观点是与DevOps的理念南辕北辙的。
DevOps是什么
目前对DevOps没有统一的定义,按照我的理解,DevOps是一种高效拉通各个职能,保证持续快速交付客户价值的方法实践。
DevOps(Develop + Operation)是关系研发流程里所有人的事情,之前有同事对DevOps做过很形象的比喻:敏捷是把产品、开发和测试绑在一起背锅,而DevOps则是把产品、开发、测试和运维都绑在一起背锅。它所代表的不仅仅是工具或是脚本,而是工程实践、研发方式、和交付态度,它将影响到我们所有人。而一旦你开始习惯它,它就会变成水和空气那样的必需品,不注意感知不到,但再也离不开。 另外,DevOps不是飘在空中的一个概念(它现在还没有非常官方的明确定义),它是跟具体落地息息相关的。所谓千人千面,每一个团队都会去寻找一个最适合他们当下情况的DevOps实践。影响的因素有很多,团队成熟度,产品特点,用户特点,现有组织架构等都是需要考虑的因素。
下面我用一个例子来说一下怎么开始。
例子:在线短信网关服务
宇宙短信公司为用户提供短信网关服务,他们的网关服务包含多个模块,如发送、计费、认证等等。同时,他们还提供多种语言的SDK,方便用户集成,如Python、Java、Go等等。公司按服务模块分成了多个组,他们共同维护一些公共模块的代码。
我们来分析一下这家公司的团队情况及他们的业务特点:
- 他们提供在线的网关服务,用户通过SDK调用他们的服务,所以他们的服务要对SDK保持兼容,但服务可以向前兼容的方式升级
- SDK的升级分为两部分,一是该公司将SDK发布到线上供客户下载,而是客户将新的SDK替换掉旧的,因此,对SDK版本的兼容性就需要保证
- 像计费这样的模块,不会被用户直接使用,不需要做接口上的兼容,但是需要保证数据的正确性
- 存在一些公共模块的代码,会被所有人使用到,因此对这部分模块的版本管理就相对重要一些
假设这家公司已经搭建了私有的Gitlab服务,每个产品有独立的Group,每个模块有独立的Project,公共模块也是一样,有一个公共模块的名字就叫common。第一步我们要做些什么呢?
从梳理研发流程开始
先不要急着搭建Jenkins或是其它CI/CD工具,也先不去管云原生这些东西,顶住各类DevOps工具的诱惑,很多工具号称可以一键给你带来DevOps能力,它可能可以做到,但此时先放一边。 第一步:Code Less,Think More! 我们先看一下当前是怎么工作的,我们是怎么开发的,建立什么样的分支,各个模块之间怎么协调,流程各个阶段怎么流转,构建在哪做的,打包又是怎么搞的,公共模块修改了之后怎么同步到所有模块的,等等。敏捷里面小步迭代,持续反馈的思想用在这里是非常合适的,我的建议是先梳理出一张当前研发的流程图,它可能很粗,比如下面这样:

很多人会觉得这算什么研发流程?别急,这只是我们的第一个版本,让我们来一步步细化它。
第二步,我们在每一个阶段上添加与之相关的角色。这时候有了下面这张图。

从这张图上我们可以看出:
- 有产品经理来梳理用户需求
- 测试由开发人员自己完成
- 发布也是开发人员自己完成
- 部署的事情责任不明确,可能谁都会做
第三步,我们分析每个阶段向下一阶段交付的标的物,并把它标注在图上。注意,这里一定要从被流转阶段的视角去分析,比如部署阶段,分析一些用到了哪些标的物才能完成这一阶段的工作。
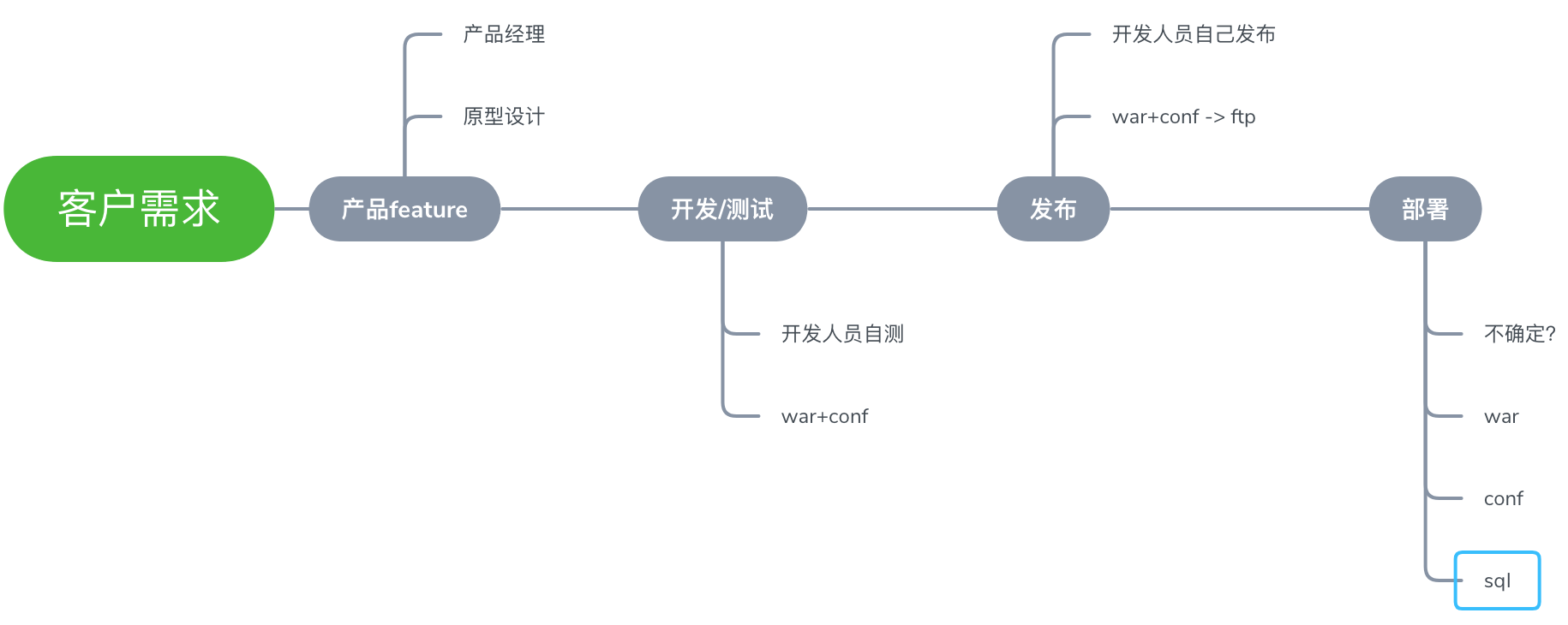
宇宙短信公司在开发、测试、发布时候的标的物都是war和conf配置文件,但是在部署的时候多了个SQL。我们可以看出这家公司是以Java为主要技术栈的,那这个SQL是怎么管理的呢?这里可能存在问题。另外这些war和conf文件是以什么方式在各个阶段间流转的呢?通过交流我们发现,有些是在代码中的,如conf配置,有些是开发人员自己打包提供的,如war。这中间存在着很多的沟通环节,还有打包的时候,公共模块的代码集成的是什么版本,这些完全取决于某个开发人员当时的状态。显然,这种做法极易出错,且效率不高。
先搞定模块的构建
请大家想一想,我们在各个阶段间沟通流转,尤其是研发之后的阶段,所说的是什么?不是某段代码,也不是某个文档,而是构建的产物,即某一时刻某一个代码上构建出来的标的物。它往往有一个唯一的标识,叫作版本。有了这两个概念,我们在交流的时候就可以说请把宇宙短信1.0版本的接口文档发给我,或者是这个问题我在宇宙微信2.0版本上遇到了。
构建物究竟是什么?它需要包含哪些东西呢?简而言之,它需要包含后面部署和对外交付相关的所有东西,包括:
- 编译好的模块,如golang代码编译成二进制程序
- 相关依赖关系
- 相关的数据变更脚本和文档,如SQL、systemd配置文件
- 对外的接口文档
- 安装、升级、回滚等工具或脚本
- 其它需要带到下一阶段的内容
怎么开始构建?
- 梳理每个模块的构建环境,并标准化(docker是一个好帮手)
- 将构建步骤、脚本和代码放在同一个地方
- 选择一种构建目标格式,如rpm,docker image,pypi等
- 构建目标存放在响应的构建物仓库里,如本地yum源
- 自动进行构建(Gitlab-CI就是一个很容易开始的方式)
下面是一个Python模块的.gitlab-ci.yml示例:
stages:
- test
- package
- publish
utest:
stage: test
except:
- tags
image: python:3-stretch
script:
- pip install -r requirements.txt -i https://pypi.douban.com/simple
- pip install pytest -i https://pypi.douban.com/simple
- python setup.py install
- pytest ./tst
python-package:
stage: package
image: python:3-stretch
script:
- echo "__version__ = '${CI_COMMIT_TAG:-master}'" > src/demo/version.py
- export PYTHONPATH=$PWD/src; python setup.py sdist
- cp dist/demo-${CI_COMMIT_TAG:-master}.tar.gz demo-${CI_COMMIT_TAG:-master}.tar.gz
artifacts:
expire_in: 7d
paths:
- demo-${CI_COMMIT_TAG:-master}.tar.gz
pypi:
stage: publish
image: scp.local:3-stretch # local image that contains scp command
only:
- tags
dependencies:
- python-package
script:
- scp demo-${CI_COMMIT_TAG:-master}.tar.gz test@pypi.local:/home/test/pypi-packages
这个文件中配置了三个stage,分别是test、package和publish,其中publish只在打tag的时候执行。三个stage都是在docker环境下执行,这样就保证了构建的标准化,最后把构建的tar.gz包发布到本地pypi源上。
注意:一个模块尽量保证只构建出一个服务。
版本号怎么确定?
一句话:能保证唯一性的任何标准都可以。
现在软件开发的发布节奏越来越快,通过计划定大版本的方式在很多时候已经不是很有必要了。所以,像宇宙短信这样的公司,我觉得精确到天的时间加上当天第几次发布就挺好,比如20190620.1,表示这个是2019年6月20号发布的第一个版本。
当然,如果你对大版本的节奏比较在意,或者你的产品是要输出给用户安装部署的,比如chrome这样的浏览器,可以采用:主要版本.次要版本.修复版本的格式,如Python 3.7.3。
import sys
sys.version_info # sys.version_info(major=3, minor=7, micro=3, releaselevel='final', serial=0)
构建完成之后先跑一跑
上面我们完成了第一个stage,构建。现在这个模块每天都有很多个版本被构建出来,那么问题来了,这些版本有的好一点,有的还是半成品,我该选择哪个呢?在一开始的阶段,我们当然没有办法也不可能快速地搭建一套测试体系出来,但有一件事是值得也是必须要做的。
那就是在一个标准环境中将构建产物跑起来。
这里有几个事情需要关注:
- 定义运行环境,如CentOS 7
- 定义安装方式,如yum install
- 确定依赖条件,如需要预先初始化某个数据库
- 确定跑起来的标准,如HTTP服务可以响应用户请求
定义产品
上面说的都是模块,通常也就是一个Github上的Project。但大部分情况下,我们所要交付的都是一个产品,特别是面对下游用户的时候,说产品的某个版本更容易交流。那么,怎么定义一个产品,又怎么把产品和模块、产品版本和模块版本联系起来呢?
首先,一个产品通常是:
- 许多模块的集合
- 以一定的方式和顺序整合这些模块
- 对环境的需求,包括硬件如网络、内存,和软件如操作系统版本
- 相关的安装部署文档
- 使用手册
的集合体。所有这些关系和材料都应该被很好的组织和管理起来。而产品的版本,对应的就是上面这些东西,只是模块有了具体的版本号,比如宇宙一站式通知中心产品2.0版本,包括:
- 短信平台1.0
- 微信平台1.2
- 电话平台2.0
这三个模块构建版本和其它那些文档、工具什么的。具体怎么管理产品和模块的关系,有很多种方法,如维护一个git仓库等等,这里要注意两点:
- 产品的版本号一旦确定,内容就应该确定下来,不可再被更改,如果有更改,就增加版本号
- 应该能通过产品版本找到每个模块版本,并进而找到每个模块对应这个产品的代码版本,这就是通过版本号进行回溯
Next…
有了上面这些,一个基本的构建加产品发布的框架已经初现雏形了,下一步建议重点关注两点:
- 让产品的部署可以自动化地进行
- 对产品的可用性有基本的自动化测试
我相信,到这个时候,接下来该做什么,宇宙公司应该有自己的计划和目标了,当然,我们也会在下一篇中继续探讨这个问题。