自己动手编写持续交付系统(一)
前言
持续交付系统或者持续集成系统是现代软件开发不可或缺的基础设施,尤其在大型项目中,持续交付系统的质量和效率往往极大影响开发的质量和效率。许多大型软件项目甚至有一个或多个专门的团队来开发和维护这类系统。另外,持续交付系统包含软件研发中的大量一手数据,很好地挖掘这些数据,也可以得到很多有价值的信息。
市面上有很多商业和开源的持续交付解决方案,如Bambook,Jenkins,与github深度集成的Travis-CI,面向创业团队的CodeShip,酷酷的Drone-CI等。另外在8.0+版本的gitlab里也将gitlab-ci集成了进去,作为内置的持续交付平台。
既然已经有这么多现成的工具了,那么为什么我们还要自己写一套持续交付系统呢?换言之,你为什么要重复造轮子?
重复造轮子这顶帽子太大,咱们只是在重复实现轮子,因为:
- 写一个持续交付系统很有趣
- 可以通过编写这个系统来实践分布式系统的搭建
- 可以完美适配自己的开发流程
- 可以整合其他既有的资源,如报表系统等
- 可以拿来吹牛~~
那么,一个持续交付系统需要包含哪些基本功能呢?
- 能够集成版本控制工具如subversion、git
- 能够将任务分发到多个节点上执行
- 可以定制执行的内容
- 能够保存执行的日志
- 能够方便地查看执行的结果和日志
- 能够及时地发送反馈和通知
所以,一个持续交付系统至少具有:
- 一个可视化的界面(通常是Web)
- 一个数据库或文件系统(用于保存配置和执行结果)
- 一个节点管理和分发工具(用于将任务分发到不同节点上执行)
- 一个定时任务工具(用于检测代码版本的变化和发送通知等)
这里,笔者希望通过一个具体的例子来展示一下如何开发一个持续交付系统。这个进行中的项目叫lybica,它的地址在lybicat@github,目前它还是一个玩具,将来,谁知道呢?
1. 从界面开始
1.1 第一个页面
在开始设计界面之前,让我们先回答一个问题:假设只能有一个页面,这个页面该展示什么?此处默念三十秒。。。
lybica的第一个页面是任务队列(包括没开始执行的、执行中的和已经结束的任务)。最基本的部分就是一个包含所有task的表格,如下图:
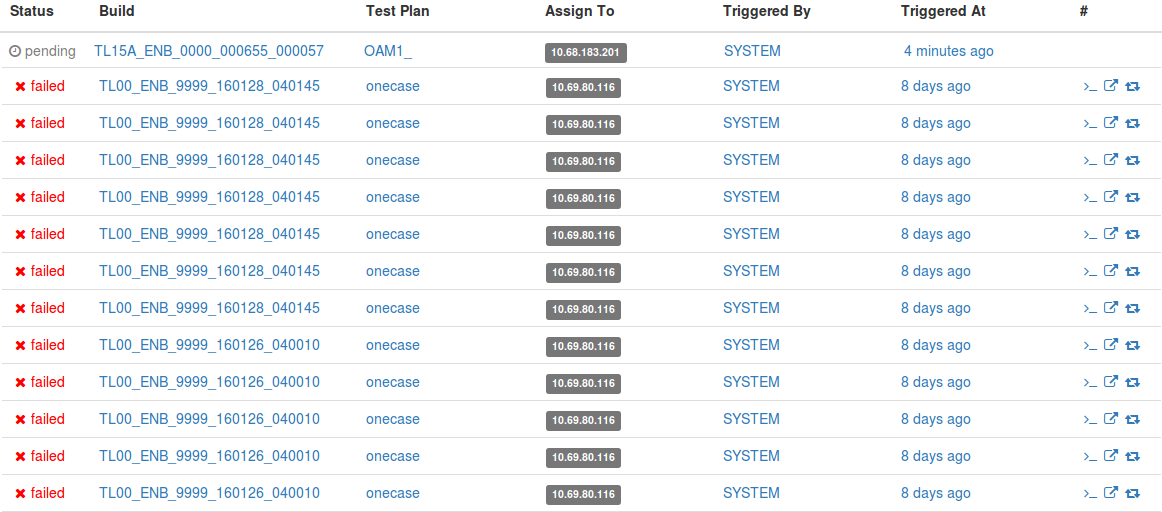
在这个页面上,一个Task包含如下信息:
- 状态(pending, running, pass, failed, aborted)
- 目标版本(这里叫Build,本质上跟Revision类似)
- 执行计划(对应与Jenkins里的Job,包含执行内容等配置)
- 执行节点(这个任务将会被分配到的目标节点)
- 触发源(如Git的变化、手工触发、按时间触发等)
- 创建时间
- 相应的操作(如Rerun,Abort等)
- 相应的资源链接(如Console Output,Log Artifacts等)
其实这里隐含这我们的第一个用户场景,可能也是最重要的那个:
作为一个开发者,当我在持续交付系统上注册了我的项目,并且配置好了相应的执行计划后,我希望当这个计划被执行后能够生成任务,并且我能够看到任务的各种信息,如成功、失败,相应的日志等。
这样,我们知道,对于上面这个用户场景,除了上面这个任务页面之外,我们可能还需要以下几个页面来满足它:
- 执行计划的查看和编辑页面
- 触发执行计划的查看和配置页面
- 实时查看某一个任务进度的页面
1.2 执行计划页面
这个页面包含两个基本的功能:查看和编辑。其中编辑又包含新增、修改和删除等功能。我们先看查看功能,它类似于任务列表,所以可以如下图这样实现:

在这个页面上,我们可以看到,一个plan包含:
- 名字(通常是唯一的)
- 测试集合
- 执行环境
- 修改按钮
- 执行按钮
而编辑方面,新增和修改可以合二为一,而删除可以在修改的时候加一个删除按钮。这样整个编辑功能可以简化为一个表单加一个新增按钮,如下图:
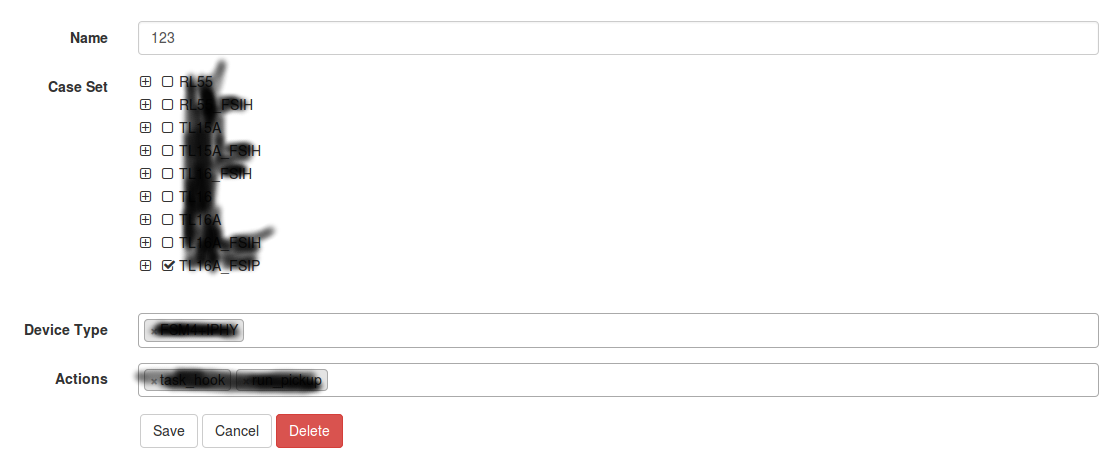
而在编辑页面,我们发现,除了查看页面里展示的那些信息之外,一个plan还需要包括:
- 执行内容,这里称之为Actions
- 变量设置,这个截图上没有展示,但在实际应用中非常重要
我们最终的实现将查看和编辑合在了一个页面上,编辑表单默认隐藏,点击编辑按钮才会显示。
1.3 触发器查看和管理页面
触发执行计划的功能,我们称之为触发器(Trigger)。
熟悉Jenkins的人都知道,Jenkins有很多的Trigger插件,可以支持各种的触发条件(如Subversion,Git,URL Change等)。Jenkins的触发采用的是一种轮询方式,最小粒度为1分钟,当两次轮询的结果发生变化,即产生新的任务。对于轮询间隔内究竟发生了几次变化,Jenkins并不关心,它只会采用最后的一次变化的版本,这一点跟gitlab-ci和travis这样的不一样,在gitlab-ci中,没一个commit都会被触发,无论其间隔是多少。
另一种常见的触发方式是按时间触发,最典型的就是cron,比如每天晚上8:00开始进行构建。
基于这些考虑,在触发器的设计上,我们考虑三种不同形式的触发器:
- 事件轮询
- 类似cron的调度方式
- 类似webhook的事件触发(通常来自于外部如gitlab)
类似webhook的事件触发不需要具体的配置界面,有一个API接口就OK了,关于这一部分,我们在后续详细介绍触发机制的时候说明。
对于事件轮询的页面,同样包含查看和编辑两个部分,参照执行计划页面的做法,我们把两者合一,见下图:
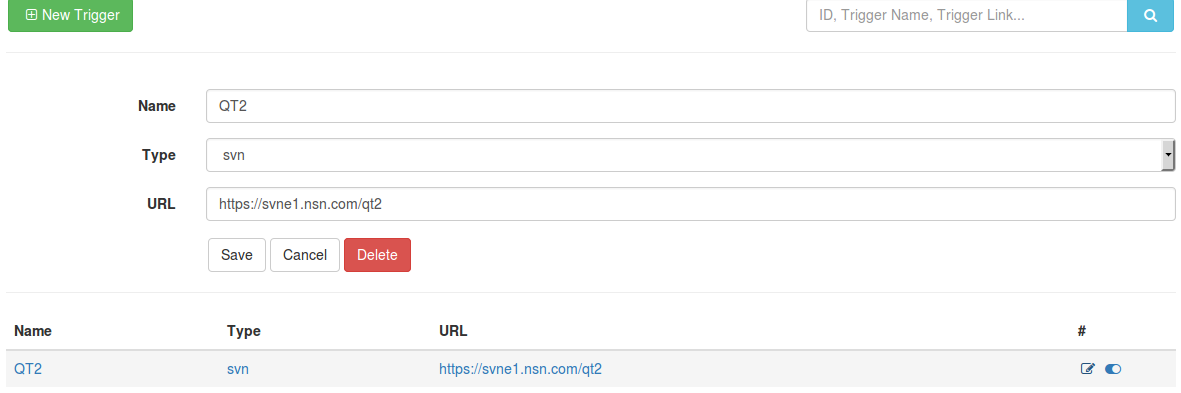
相对于Plan来说,Trigger多了一个disable/enable的功能,其它方面基本一致。
1.4 Console Output页面
对于实时查看某一个任务的进度和输出,参照Jenkins的命名方式,我们也叫它为Console Output。所以这个页面的要求是:
- 与task关联
- 实时更新输出
可以很简单,如下图:

2. 数据的保存
这里的数据指的是控制数据,即用户配置的Trigger,Plan以及执行的Task等。Jenkins采用xml文件来存储这些内容,而笔者更倾向于数据库。
在lybica这个项目中,数据存储采用了MongoDB。之所以用它而不是像MySQL这样的关系型数据库,主要是为了更方便地应对变化。以Trigger为例,SVN和Web在数据结构上就有很大的不同,比如SVN需要认证,要解析的是revision号,web考虑的是内容本身,可能需要带token等等。
lybica系统采用了mongoose作为数据持久话方案,以Trigger为例,它的model如下:
var triggerSchema = mongoose.Schema({
name: String,
type: String,
url: String,
content: Mixed,
createby: {type: String, default: 'SYSTEM'},
createat: {type: Date, default: Date.now},
updateby: {type: String, default: 'SYSTEM'},
updateat: {type: Date, default: Date.now},
disabled: {type: Boolean, default: false},
removed: {type: Boolean, default: false},
});
triggerSchema.plugin(mongoosePaginate);
module.exports.Trigger = mongoose.model('trigger', triggerSchema);
相对于Django、Ruby on Rails那样All In One的框架,在这里轻量级的框架可能更合适。而我们所需要的本质上是一个数据的存取服务,所以这里采用RESTful的方式,用了一个NodeJS的小框架restify。
而API的设计我们只关注对象本身(如Task,Plan,Trigger等),而所有的API就是针对这些对象的增、删、改操作。
以lybica系统的Trigger API为例:
module.exports = {
'/api/triggers': {
get: function(req, res, next) {
var filterCond = _.clone(req.params);
delete filterCond.page;
delete filterCond.limit;
filterCond.removed = filterCond.removed === 'true';
return filterObjects(Trigger, filterCond, '-updateat', req, res, next);
},
post: function(req, res, next) {
var trigger = new Trigger();
_.keys(req.body).forEach(function(attr) {
trigger[attr] = req.body[attr];
});
trigger.save(function(err, p) {
if (err) return next(err);
return res.send(200, {id: p._id});
});
},
},
'/api/trigger/:id': {
get: function(req, res, next) {
Trigger.findById(req.params.id)
.then(function(trigger) {
if (trigger === null) return res.send(404);
return res.send(trigger);
});
},
post: function(req, res, next) {
Trigger.findById(req.params.id)
.then(function(trigger) {
if (trigger === null) return res.send(404);
_.keys(req.body).forEach(function(k) {
trigger[k] = req.body[k];
});
trigger.save().then(function(t) {
return res.send(200, t);
});
});
},
del: function(req, res, next) {
Trigger.findByIdAndUpdate(req.params.id, {$set: {removed: true}}, function(err, trigger) {
if (err) return next(err);
return res.send(200);
});
}
},
'/api/trigger/:id/enable': {
put: function(req, res, next) {
Trigger.findByIdAndUpdate(req.params.id, {$set: {disabled: false}}, function(err, trigger) {
if (err) return next(err);
return res.send(200);
})
}
},
'/api/trigger/:id/disable': {
put: function(req, res, next) {
Trigger.findByIdAndUpdate(req.params.id, {$set: {disabled: true}}, function(err, trigger) {
if (err) return next(err);
return res.send(200);
})
}
},
};
可以看到,我们充分利用了HTTP的method来定义不同的操作类型:
- GET用于获取数据
- POST用于创建数据
- PUT用于更新数据
- DELETE用于删除数据。
3. 执行日志的存储
对于一个持续集成系统究竟要保存多少执行日志,一直没有一个定论,因为有的时候执行日志和构建产物会很大,大到一次构建就会产生数十G的日志。而另一方面,由于这个系统使用的频繁,会产生数量庞大的小日志文件,因此对于这些执行日志的存储是必须要关注的一个问题。
Jenkins在这方面常用的做法是将所有的日志都保存在master上,在日志数量和体积变得庞大的时候,master就会变成IO的瓶颈。
所以,我们希望的日志存储功能要有以下几个特点:
- 通过HTTP的方式进行存取
- 可以独立部署和服务
- 能够对日志文件进行压缩以减少小文件的数量和IO读取效率
- 能够在线浏览和访问
- 能够方便地扩容
合适的分布式存储方案还是不少的,在lybica项目中我们选用了常见的HDFS。同时为了减少小文件的数量和进行压缩,对每个Task产生的所有日志压缩为ZIP进行存储。而在访问的时候,由于HDFS在随机读取上的限制,我们在服务端缓存需要读取的日志,然后实时解压缩。
具体的实现,可以参照lybica-hdfs-viewer。
4. 管理执行节点
执行节点就是真正干活的机器(在Jenkins上它被称之为Slave),当然如果我们有好的云基础设施,而我们的应用又可以运行于通用平台的话,这一部分就是申请资源,分配资源的事情。但是人生不如意十之八九,对于大部分人来说,我们没有好的云基础设施,或者说不够好用,而我们的应用又与平台相关。
这里我们采用客户端注册的方式来进行节点管理,类似于Gitlab-CI。我们需要一种全双工的协议来进行客户端和服务端的协作,这里我们选择了Websocket协议,因为它基于HTTP,可以和restify一起工作得很好。
从实现上,我们会在数据服务上同时起一个websocket服务端,而每个执行节点,会作为一个websocket客户端与之通信,当有任务过来的时候,服务端会把任务“推”给客户端。我们希望这个客户端尽可能地简单,以避免以后频繁升级的麻烦。以下为一个简单的工作流:
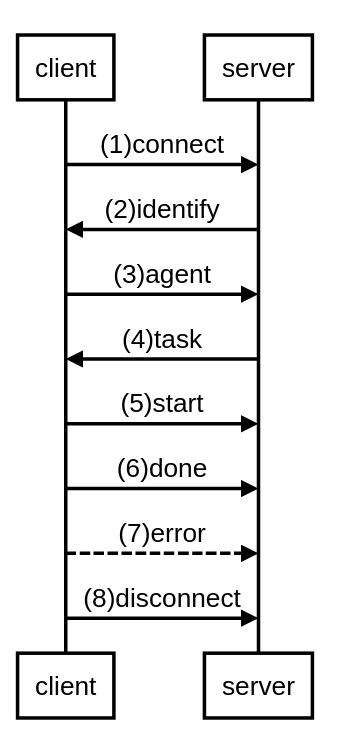
简单说明一下以上1-8步具体的操作:
- 客户端启动,连上服务端
- 服务端将客户端的唯一标识分配给它,通常为IP地址
- 客户端上报详细的配置信息,包括操作系统等,服务端收到后更新对应的记录
- 服务端分配任务给客户端
- 客户端上报服务端开始执行任务
- 客户端上报服务端任务结束
- 当客户端遇到错误的时候,上报错误信息给服务端
- 如果客户端不再使用,结束进程,关闭与服务端的连接
对于websocket服务端,可以参照ws.js。
对于websocket客户端,可以参照lybica-agent。
5. 配置触发器来产生任务
前面页面设计的时候,提到关于触发器的设计,从数据存储的角度讲,我们保存触发器的类型以及相应的信息就可以了。但是我们需要一个轮询器来对每一个触发器进行轮询,如果发现触发项有更新,就执行与之相关的Plan。
所以,首先,我们要有一个轮询器,这个轮询器会运行在数据服务相同的地方,每隔一分钟轮询一次。使用Javascript,最简单的可以使用setInterval函数。简单的例子如下:
function poll() {
console.log('polling...');
// TODO
}
setInterval(poll, 60000);
更详细的实现,可以参照cron.js。
6. 实时查看执行的结果
对于单元测试或者其他轻量级的测试来说,测试的时间一般很短,几秒至几分钟就结束了。但是对于端到端的自动化测试或者其他诸如稳定性测试、性能测试等,这个测试时间可以很长,长达数小时至数天。这个时候,对于执行情况的实时查看就变得比较重要了。这里我们比较一下Jenkins和Lybica的两种实现方式。
Jenkins的实现方式是,所有的job的Console Output都是以文件形式存储在Jenkins Master上的,通过管道的方式把输出不断地append到那个名叫log的文件中。访问的时候,通过HTTP访问那个log文件,以polling的方式来不断获取文件的更新,从而达到实时查看的目的。如下图:
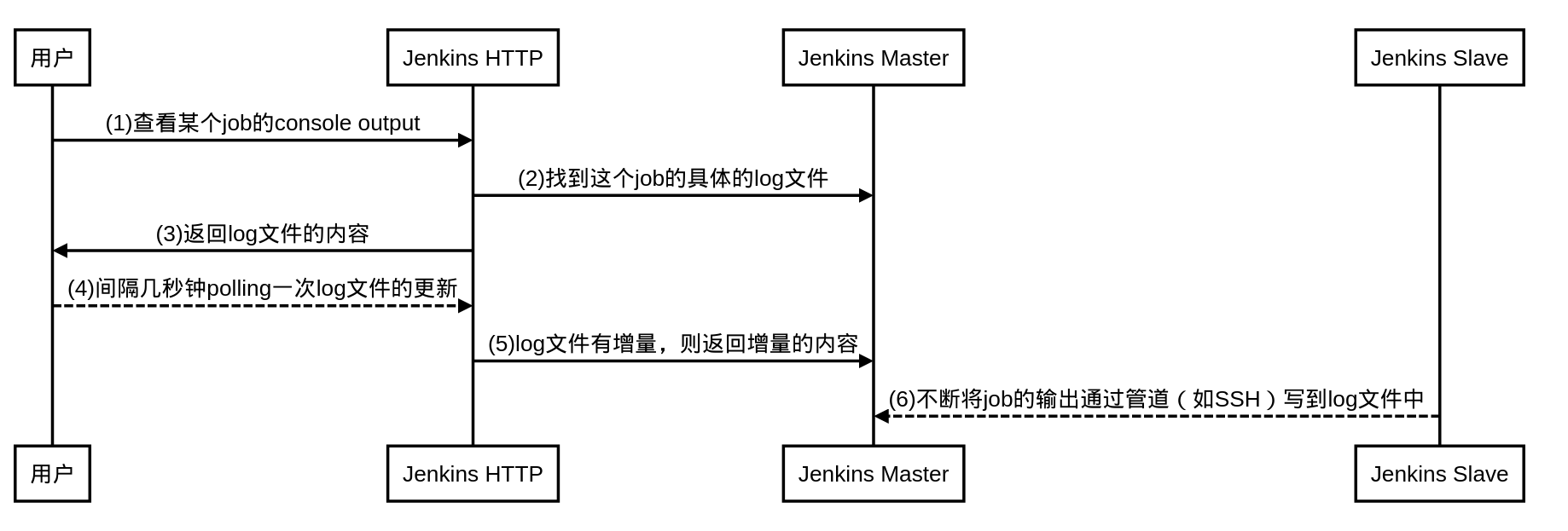
Lybica的Platform(可以类比于Jenkins Master)以数据库的形式保存各种配置和任务信息,但不保存执行记录,这也包括Console Output。因此Lybica在这块的实现与Jenkins有些不同。在Task没有完成的时候,Console Output以文件形式保存在Agent(类似Jenkins Slave)上,而Task完成之后,它也会被保存到独立的存储上(这里是HDFS)。Task完成之后,查看Console Output和查看其它构建log没有区别,这里我们单讲Task没有完成时候,Console Output的查看机制。
流程如下:
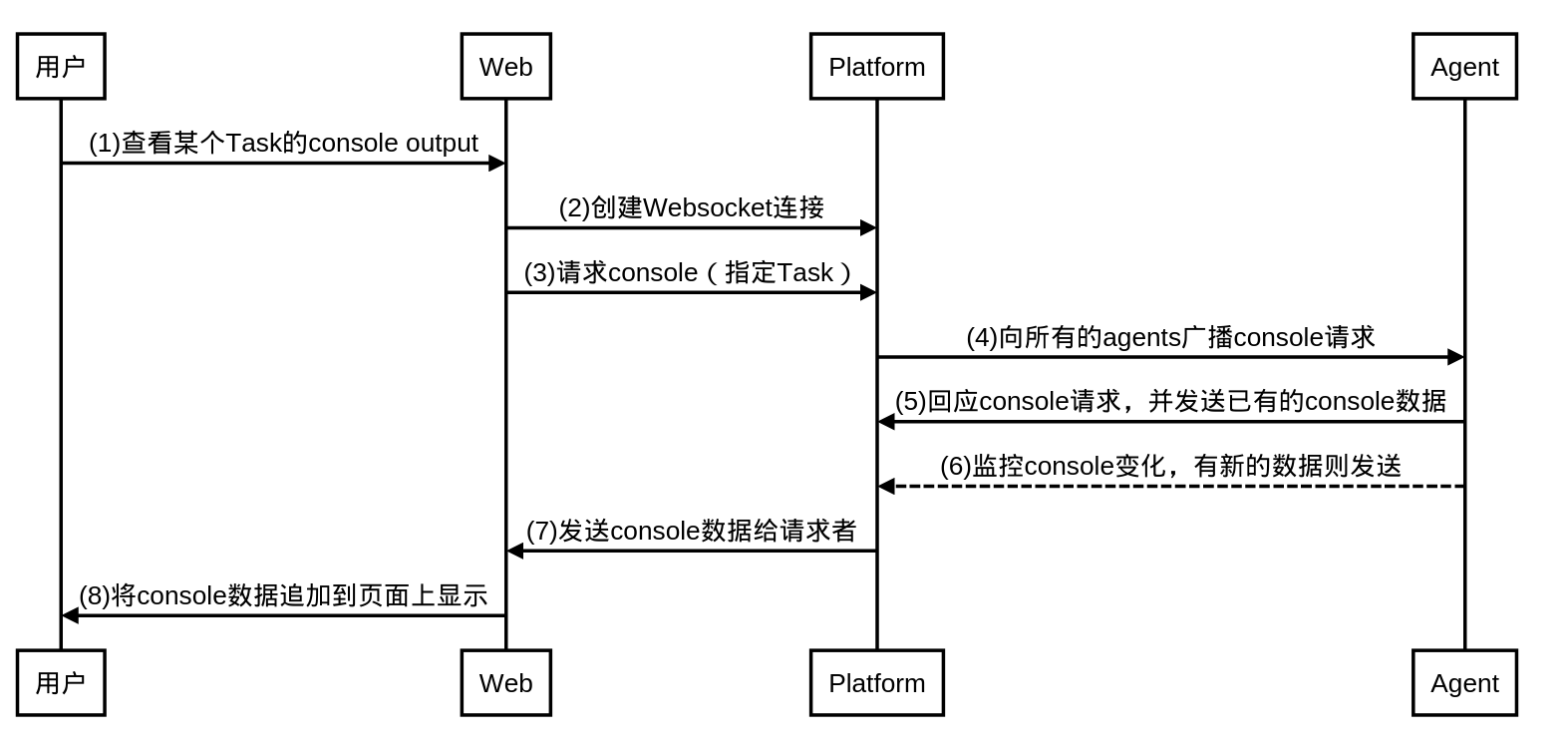
- 无论是用户打开的Web页面,还是Agent都是Websocket的client
- Platform为websocket的server,所有的console数据通过server在各个client间传输
7. 优雅地部署和升级
Jenkins的插件部署和升级,对于一个繁忙的系统来说是个麻烦。因为在这个中间,需要等待所有正在执行的任务结束,并重启Jenkins服务。而这个期间如果遇到问题需要回退,也需要等待任务结束并重启。
而我们真正需要的是一个优雅的系统,就像facebook,即使每周都在更新,但是用户却从未受到打扰。
lybica把Web,数据服务和Agent独立成不同的project。Web是真正的静态网站,而数据服务也仅仅是数据API。数据服务lybica-platform和Agent服务lybica-agent都是nodejs应用,借助于pm2,可以实现在代码更新后的服务更新只需一条pm2 restart all,而对于HTTP服务来说,这个时间足够短暂。
而在部署上,docker是一个很好的方案。